
In a multi-region deployment, the geo-partitioned replicas topology is a good choice for tables with the following requirements:
- Read and write latency must be low.
- Rows in the table, and all latency-sensitive queries, can be tied to specific geographies, e.g., city, state, region.
- Regional data must remain available during an AZ failure, but it's OK for regional data to become unavailable during a region-wide failure.
See It In Action - Read about how an electronic lock manufacturer and multi-national bank are using the Geo-Partitioned Replicas topology in production for improved performance and regulatory compliance.
Prerequisites
Fundamentals
- Multi-region topology patterns are almost always table-specific.
- Review how data is replicated and distributed across a cluster, and how this affects performance. It is especially important to understand the concept of the "leaseholder". For a summary, see Reads and Writes in CockroachDB. For a deeper dive, see the CockroachDB Architecture documentation.
- Review the concept of locality, which makes CockroachDB aware of the location of nodes and able to intelligently place and balance data based on how you define replication controls.
- Review the recommendations and requirements in our Production Checklist.
- This topology doesn't account for hardware specifications, so be sure to follow our hardware recommendations and perform a POC to size hardware for your use case.
- Adopt relevant SQL Best Practices to ensure optimal performance.
Cluster setup
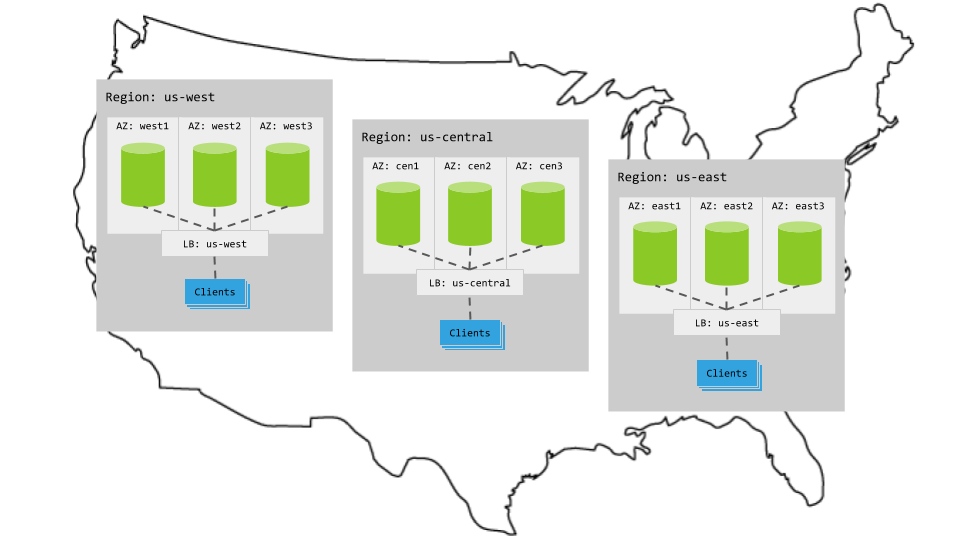
Each multi-region topology pattern assumes the following setup:
Hardware
3 regions
Per region, 3+ AZs with 3+ VMs evenly distributed across them
Region-specific app instances and load balancers
- Each load balancer redirects to CockroachDB nodes in its region.
- When CockroachDB nodes are unavailable in a region, the load balancer redirects to nodes in other regions.
Cluster
Each node is started with the --locality flag specifying its region and AZ combination. For example, the following command starts a node in the west1 AZ of the us-west region:
$ cockroach start \
--locality=region=us-west,zone=west1 \
--certs-dir=certs \
--advertise-addr=<node1 internal address> \
--join=<node1 internal address>:26257,<node2 internal address>:26257,<node3 internal address>:26257 \
--cache=.25 \
--max-sql-memory=.25 \
--background
Configuration
Geo-partitioning requires an Enterprise license.
Summary
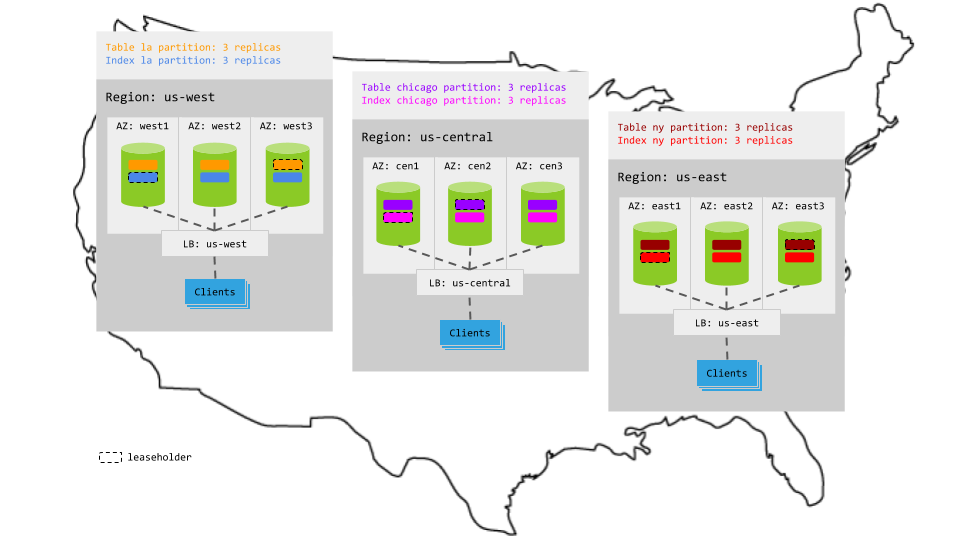
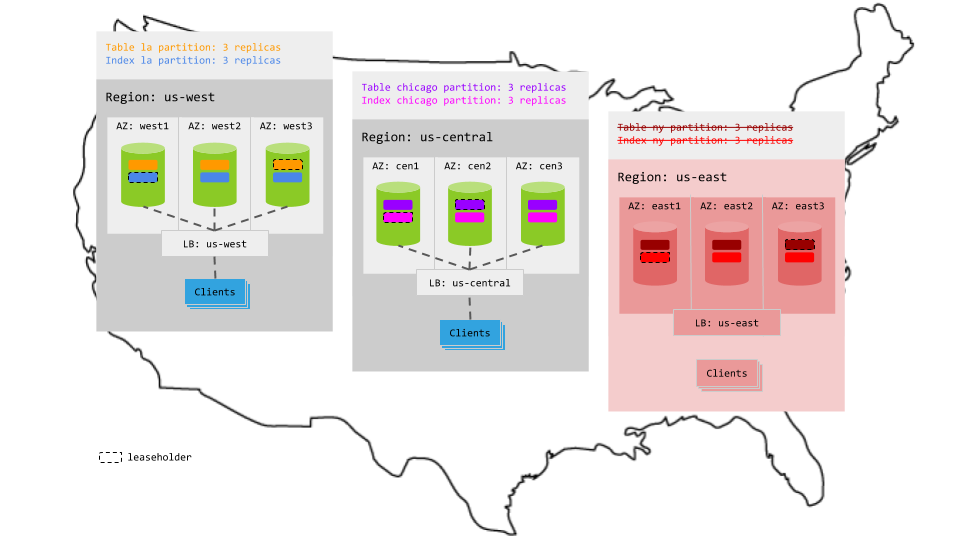
Using this pattern, you design your table schema to allow for partitioning, with a column identifying geography as the first column in the table's compound primary key (e.g., city/id). You tell CockroachDB to partition the table and all of its secondary indexes by that geography column, each partition becoming its own range of 3 replicas. You then tell CockroachDB to pin each partition (all of its replicas) to the relevant region (e.g., LA partitions in us-west, NY partitions in us-east). This means that reads and writes in each region will always have access to the relevant replicas and, therefore, will have low, intra-region latencies.
Steps
Assuming you have a cluster deployed across three regions and a table and secondary index like the following:
> CREATE TABLE users (
id UUID NOT NULL DEFAULT gen_random_uuid(),
city STRING NOT NULL,
first_name STRING NOT NULL,
last_name STRING NOT NULL,
address STRING NOT NULL,
PRIMARY KEY (city ASC, id ASC)
);
> CREATE INDEX users_last_name_index ON users (city, last_name);
A geo-partitioned table does not require a secondary index. However, if the table does have one or more secondary indexes, each index must be partitioned as well. This means that the indexes must start with the column identifying geography, like the table itself, which impacts the queries they'll be useful for. If you cannot partition all secondary indexes on a table you want to geo-partition, consider the Geo-Partitioned Leaseholders pattern instead.
If you do not already have one, request a trial Enterprise license.
Partition the table by
city. For example, assuming there are three possiblecityvalues,los angeles,chicago, andnew york:> ALTER TABLE users PARTITION BY LIST (city) ( PARTITION la VALUES IN ('los angeles'), PARTITION chicago VALUES IN ('chicago'), PARTITION ny VALUES IN ('new york') );This creates distinct ranges for each partition of the table.
Partition the secondary index by
cityas well:> ALTER INDEX users_last_name_index PARTITION BY LIST (city) ( PARTITION la VALUES IN ('los angeles'), PARTITION chicago VALUES IN ('chicago'), PARTITION ny VALUES IN ('new york') );This creates distinct ranges for each partition of the secondary index.
For each partition of the table and its secondary index, create a replication zone that constrains the partition's replicas to nodes in the relevant region:
Tip:The
<table>@*syntax lets you create zone configurations for all identically named partitions of a table, saving you multiple steps.> ALTER PARTITION la OF INDEX users@* CONFIGURE ZONE USING constraints = '[+region=us-west]'; ALTER PARTITION chicago OF INDEX users@* CONFIGURE ZONE USING constraints = '[+region=us-central]'; ALTER PARTITION ny OF INDEX users@* CONFIGURE ZONE USING constraints = '[+region=us-east]';To confirm that partitions are in effect, you can use the
SHOW CREATE TABLEorSHOW PARTITIONSstatement:> SHOW CREATE TABLE users;table_name | create_statement +------------+----------------------------------------------------------------------------------------------------+ users | CREATE TABLE users ( | id UUID NOT NULL DEFAULT gen_random_uuid(), | city STRING NOT NULL, | first_name STRING NOT NULL, | last_name STRING NOT NULL, | address STRING NOT NULL, | CONSTRAINT "primary" PRIMARY KEY (city ASC, id ASC), | INDEX users_last_name_index (city ASC, last_name ASC) PARTITION BY LIST (city) ( | PARTITION la VALUES IN (('los angeles')), | PARTITION chicago VALUES IN (('chicago')), | PARTITION ny VALUES IN (('new york')) | ), | FAMILY "primary" (id, city, first_name, last_name, address) | ) PARTITION BY LIST (city) ( | PARTITION la VALUES IN (('los angeles')), | PARTITION chicago VALUES IN (('chicago')), | PARTITION ny VALUES IN (('new york')) | ); | ALTER PARTITION chicago OF INDEX defaultdb.public.users@primary CONFIGURE ZONE USING | constraints = '[+region=us-central]'; | ALTER PARTITION la OF INDEX defaultdb.public.users@primary CONFIGURE ZONE USING | constraints = '[+region=us-west]'; | ALTER PARTITION ny OF INDEX defaultdb.public.users@primary CONFIGURE ZONE USING | constraints = '[+region=us-east]'; | ALTER PARTITION chicago OF INDEX defaultdb.public.users@users_last_name_index CONFIGURE ZONE USING | constraints = '[+region=us-central]'; | ALTER PARTITION la OF INDEX defaultdb.public.users@users_last_name_index CONFIGURE ZONE USING | constraints = '[+region=us-west]'; | ALTER PARTITION ny OF INDEX defaultdb.public.users@users_last_name_index CONFIGURE ZONE USING | constraints = '[+region=us-east]' (1 row)> SHOW PARTITIONS FROM TABLE users;database_name | table_name | partition_name | parent_partition | column_names | index_name | partition_value | zone_config +---------------+------------+----------------+------------------+--------------+-----------------------------+-----------------+---------------------------------------+ defaultdb | users | la | NULL | city | users@primary | ('los angeles') | constraints = '[+region=us-west]' defaultdb | users | chicago | NULL | city | users@primary | ('chicago') | constraints = '[+region=us-central]' defaultdb | users | ny | NULL | city | users@primary | ('new york') | constraints = '[+region=us-east]' defaultdb | users | la | NULL | city | users@users_last_name_index | ('los angeles') | constraints = '[+region=us-west]' defaultdb | users | chicago | NULL | city | users@users_last_name_index | ('chicago') | constraints = '[+region=us-central]' defaultdb | users | ny | NULL | city | users@users_last_name_index | ('new york') | constraints = '[+region=us-east]' (6 rows)
As you scale and add more cities, you can repeat steps 2 and 3 with the new complete list of cities to re-partition the table and its secondary indexes, and then repeat step 4 to create replication zones for the new partitions.
In testing, scripting, and other programmatic environments, we recommend querying the crdb_internal.partitions internal table for partition information instead of using the SHOW PARTITIONS statement. For more information, see Querying partitions programmatically.
Characteristics
Latency
Reads
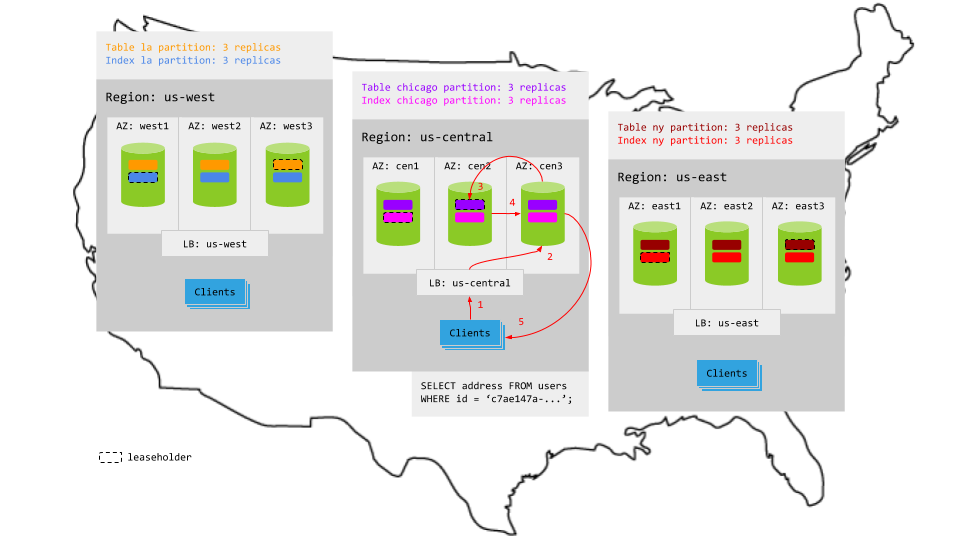
Because each partition is constrained to the relevant region (e.g., the la partitions are located in the us-west region), reads that specify the local region key access the relevant leaseholder locally. This makes read latency very low, with the exception of reads that do not specify a region key or that refer to a partition in another region; such reads will be transactionally consistent but will not have local latencies.
For example, in the animation below:
- The read request in
us-centralreaches the regional load balancer. - The load balancer routes the request to a gateway node.
- The gateway node routes the request to the leaseholder for the relevant partition.
- The leaseholder retrieves the results and returns to the gateway node.
- The gateway node returns the results to the client.
Writes
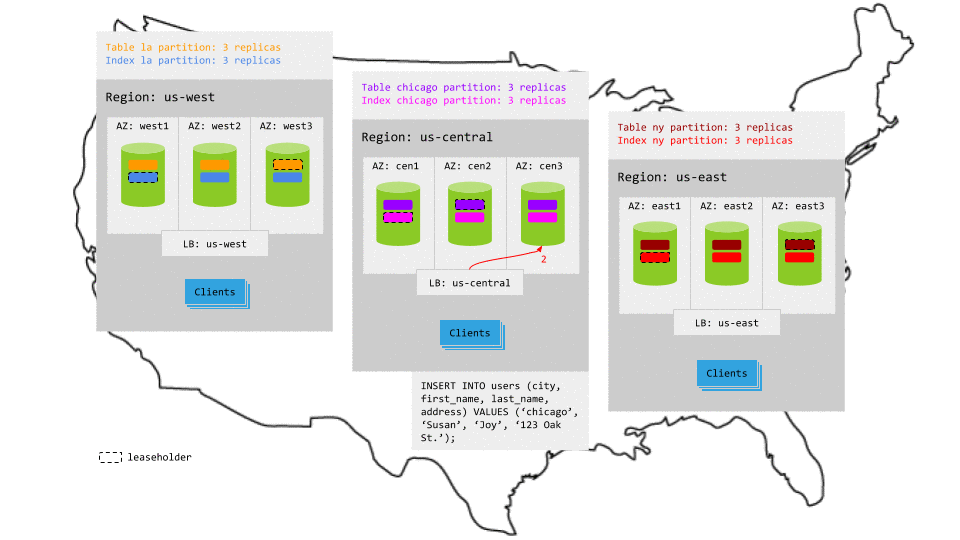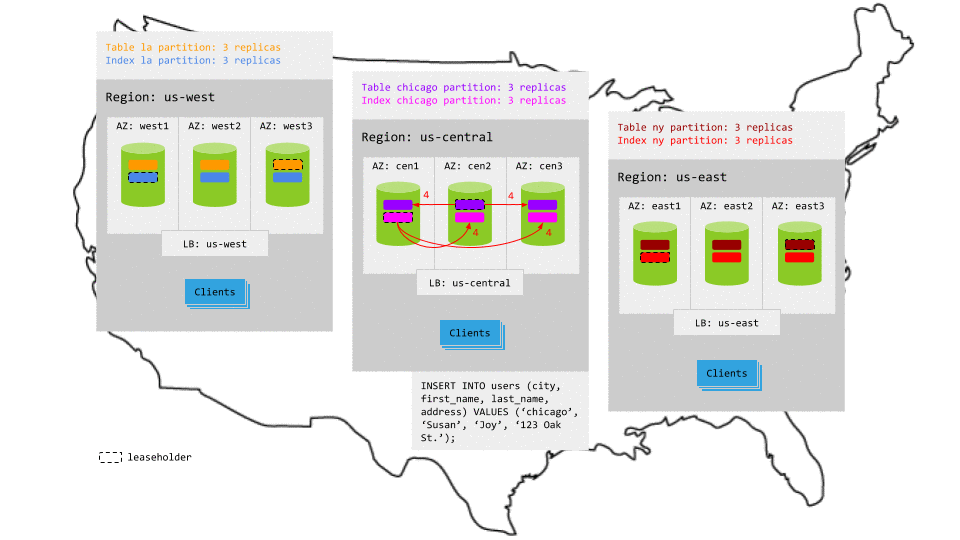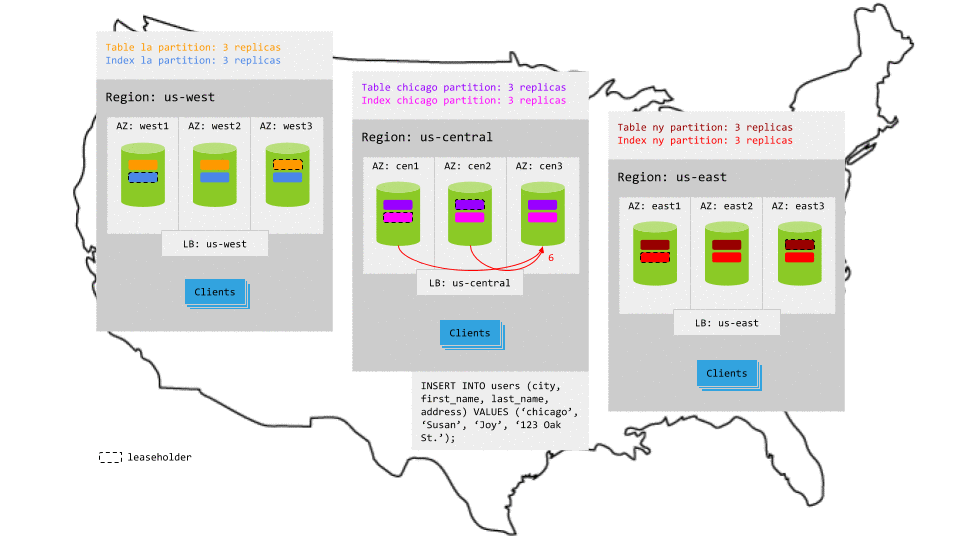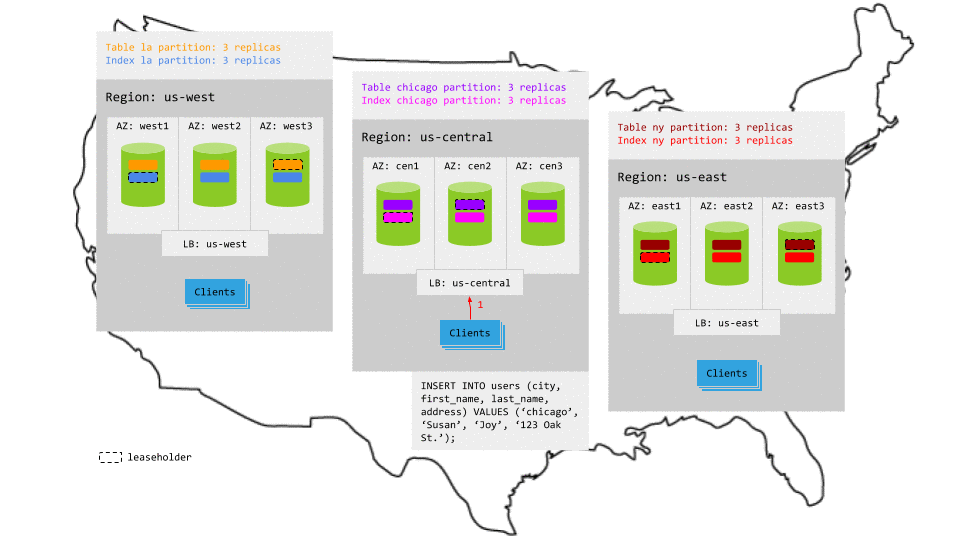
Just like for reads, because each partition is constrained to the relevant region (e.g., the la partitions are located in the us-west region), writes that specify the local region key access the relevant replicas without leaving the region. This makes write latency very low, with the exception of writes that do not specify a region key or that refer to a partition in another region; such writes will be transactionally consistent but will not have local latencies.
For example, in the animation below:
- The write request in
us-centralreaches the regional load balancer. - The load balancer routes the request to a gateway node.
- The gateway node routes the request to the leaseholder replicas for the relevant table and secondary index partitions.
- While each leaseholder appends the write to its Raft log, it notifies its follower replicas, which are in the same region.
- In each case, as soon as one follower has appended the write to its Raft log (and thus a majority of replicas agree based on identical Raft logs), it notifies the leaseholder and the write is committed on the agreeing replicas.
- The leaseholders then return acknowledgement of the commit to the gateway node.
- The gateway node returns the acknowledgement to the client.
Resiliency
Because each partition is constrained to the relevant region and balanced across the 3 AZs in the region, one AZ can fail per region without interrupting access to the partitions in that region:
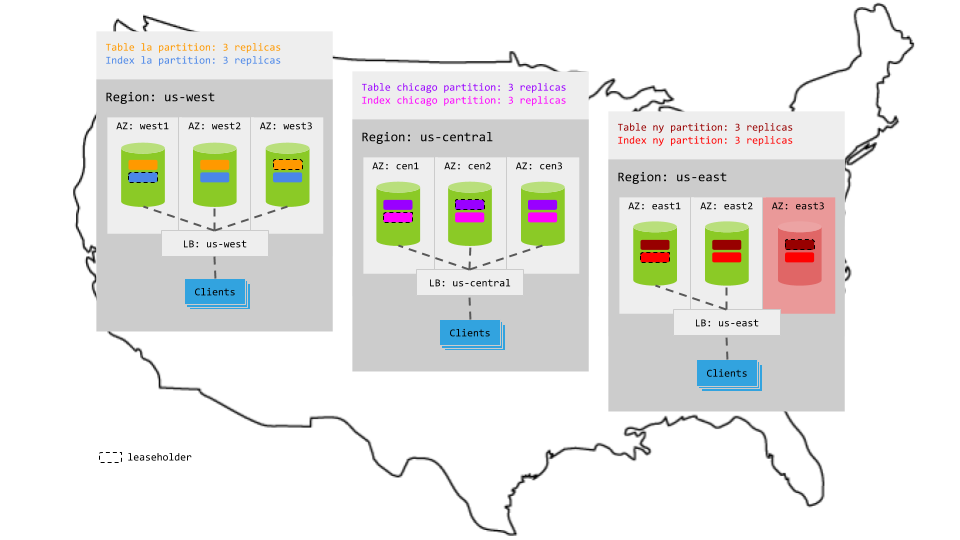
However, if an entire region fails, the partitions in that region become unavailable for reads and writes, even if your load balancer can redirect requests to a different region:
Tutorial
For a step-by-step demonstration of how this pattern gets you low-latency reads and writes in a broadly distributed cluster, see the Low Latency Multi-Region Deployment tutorial.
See also
-
- Single-region
- Multi-region
Was this helpful?