
CockroachDB Enterprise changefeeds can stream change data out to Apache Kafka with different configuration settings and options. Confluent Cloud provides a fully managed service for running Apache Kafka as well as the Confluent Cloud Schema Registry.
A schema registry is a repository for schemas, which allows you to share and manage schemas between different services. Confluent Cloud Schema Registries map to Kafka topics in your Confluent Cloud environment.
In this tutorial, you will set up a changefeed to stream data from CockroachDB to a Kafka cluster in Confluent Cloud. You will also connect a Schema Registry that retrieves the schemas from your changefeed's messages.
An overview of the workflow involves creating and connecting the following:
- Confluent Cloud Kafka cluster
- Confluent Schema Registry
- Changefeed streaming to your Confluent Cloud Kafka cluster
Before you begin
You will need the following set up before starting this tutorial:
- A CockroachDB cluster. You can use a CockroachDB Cloud or CockroachDB Self-Hosted cluster. If you are using CockroachDB Serverless or CockroachDB Dedicated, see the Quickstart with CockroachDB guide. For CockroachDB Self-Hosted clusters, see the install page.
- A Confluent Cloud account. See Confluent's Get started page for details.
- The Confluent CLI. See Install Confluent CLI to set this up. This tutorial uses v3.3.0 of the Confluent CLI. Note that you can also complete the steps in this tutorial in Confluent's Cloud console.
This tutorial uses the Cockroach Labs movr workload as an example database.
Step 1. Create a Confluent Cloud Kafka cluster
In this step, you'll use the Confluent CLI to create and configure a Kafka cluster.
First, ensure you are logged in to Confluent Cloud:
confluent login --save
These instructions use the --save flag to store your username and password to a local file for convenience during this tutorial, but you can omit this flag if you would prefer to manually authenticate yourself each time.
List the environments in your Confluent Cloud account:
confluent environment list
If you haven't created an environment explicitly, this command will list a default environment. You can use the default environment for this tutorial.
However, if you would prefer to create an environment, run the following command with a name for your environment:
confluent environment create {ENVIRONMENT NAME}
Set the environment that you would like to create your cluster in, using the environment's ID, which starts with env-:
confluent environment use {ENVIRONMENT ID}
Next, create a Kafka cluster:
confluent kafka cluster create movr-confluent-tutorial --cloud "gcp" --region "us-east1"
Here the name of the cluster is movr-confluent-tutorial, but you can change this for your cluster.
Note that the --cloud and --region flags are required when running the create command. See Confluent's documentation on confluent kafka cluster create.
The create command returns your new cluster's details, with a format similar to the following:
+---------------+--------------------------------------------------------+
| ID | lkc-{ID} |
| Name | movr-confluent-tutorial |
| Type | BASIC |
| Ingress | 100 |
| Egress | 100 |
| Storage | 5 TB |
| Provider | gcp |
| Availability | single-zone |
| Region | us-east1 |
| Status | PROVISIONING |
| Endpoint | SASL_SSL://pkc-4yyd6.us-east1.gcp.confluent.cloud:9092 |
| API Endpoint | https://pkac-ew1dj.us-east1.gcp.confluent.cloud |
| REST Endpoint | https://pkc-4yyd6.us-east1.gcp.confluent.cloud:443 |
+---------------+--------------------------------------------------------+
You'll need this information later in the tutorial, but you can also access this status at any time with the following command:
confluent kafka cluster describe {CLUSTER ID}
It can take up to 5 minutes for your Kafka cluster to provision. The Status field in the cluster's details will change from PROVISIONING to UP once your Kafka cluster is ready.
Step 2. Create a cluster API key and secret
In this step, you'll create an API key and secret for your Kafka cluster, which you'll need for connecting to your changefeed.
Create the API key for your Kafka cluster:
confluent api-key create --resource {CLUSTER ID}
You will receive output displaying your API and secret key.
Then, to make the consumer setup easier later in the tutorial, you can store the API key locally and set it as your active API key:
confluent api-key store --resource {CLUSTER ID}
confluent api-key use {API KEY} --resource {CLUSTER ID}
This will prompt you to enter your API and secret key. Use the --force flag if you already have a key stored in your local environment.
Step 3. Create Kafka topics
Next, you'll create the Kafka topics for your changefeed messages.
Ensure you have the correct active Kafka cluster:
confluent kafka cluster use {CLUSTER ID}
Set Kafka cluster "lkc-{ID}" as the active cluster for environment "env-{ID}".
Run the following to create a topic:
confluent kafka topic create users
users will be the topic name for this tutorial. If needed, you can change the topic name for your purposes and run the previous command for each topic you would like to create.
If you are using a Dedicated Confluent Cloud cluster, you can enable auto topic creation. For further detail, see Enable automatic topic creation.
Step 4. Create a Confluent Schema Registry
In this step, you'll create the Schema Registry in your environment.
Enable the Schema Registry for the active environment:
confluent schema-registry cluster enable --cloud "gcp" --geo "us"
The --cloud and --geo flags are required with this enable command. See the confluent schema-registry cluster enable docs for more detail. To match the Kafka cluster setup for this tutorial, the cloud is set to Google Cloud Platform and the geo to the US.
You will receive output showing the Schema Registry's ID and its endpoint URL:
+--------------+----------------------------------------------------+
| Id | lsrc-816zp7 |
| Endpoint URL | https://psrc-x77pq.us-central1.gcp.confluent.cloud |
+--------------+----------------------------------------------------+
Step 5. Create a Schema Registry API key and secret
Next, generate an API and secret key for the Schema Registry using the ID from your output:
confluent api-key create --resource {SCHEMA REGISTRY ID}
The output will display your API key and secret. You'll need these to create your Kafka consumer and start your changefeed.
Step 6. Create a Kafka consumer
In this step, you'll start a Kafka consumer for the changefeed messages.
Run the following command to create a consumer:
confluent kafka topic consume users \
--value-format avro \
--from-beginning \
--schema-registry-endpoint {SCHEMA REGISTRY ENDPOINT URL} \
--schema-registry-api-key {SCHEMA REGISTRY API KEY} \
--schema-registry-api-secret {SCHEMA REGISTRY SECRET}
In this command, you need to pass the following Schema Registry details:
For this command to run successfully, ensure that confluent kafka cluster describe {CLUSTER ID} returns a Status of UP.
Your terminal will wait for messages after this command has run successfully.
Run confluent schema-registry cluster describe to access details for the Schema Registry, if needed.
Step 7. Prepare your CockroachDB cluster
To create your changefeed, you'll prepare your CockroachDB cluster with the movr workload and enable rangefeeds.
In a new terminal window, initiate the movr workload for your cluster:
cockroach workload init movr {"CONNECTION STRING"}
Then, run the workload to generate some data:
cockroach workload run movr --duration=1m {"CONNECTION STRING"}
Start a SQL session for your CockroachDB cluster:
cockroach sql --url {"CONNECTION STRING"}
Set your organization name and Enterprise license key that you received via email:
SET CLUSTER SETTING cluster.organization = '<organization name>';
SET CLUSTER SETTING enterprise.license = '<secret>';
Before you can create an Enterprise changefeed, it is necessary to enable rangefeeds on your cluster:
SET CLUSTER SETTING kv.rangefeed.enabled = true;
Step 8. Create a changefeed
Before running the CREATE CHANGEFEED statement, you must URL-encode both the cluster's and the Schema Registry's API secret key.
Create the changefeed with the following statement:
CREATE CHANGEFEED FOR TABLE users INTO "kafka://{KAFKA ENDPOINT}?tls_enabled=true&sasl_enabled=true&sasl_user={CLUSTER API KEY}&sasl_password={URL-ENCODED CLUSTER SECRET KEY}&sasl_mechanism=PLAIN" WITH updated, format = avro, confluent_schema_registry = "https://{SCHEMA REGISTRY API KEY}:{URL-ENCODED SCHEMA REGISTRY SECRET KEY}@{SCHEMA REGISTRY ENDPOINT URL}:443";
To connect to the Kafka cluster, use the Endpoint from your cluster details and precede it with the kafka:// scheme. For example, an endpoint of pkc-4yyd6.us-east1.gcp.confluent.cloud:9092 would be: kafka://pkc-4yyd6.us-east1.gcp.confluent.cloud:9092.
Since the Kafka cluster uses SASL authentication, you need to pass the following parameters. This includes the cluster API and secret key you created in Step 2:
tls_enabled=truesasl_enabled=truesasl_user={CLUSTER API KEY}sasl_password={URL-ENCODED CLUSTER SECRET KEY}sasl_mechanism=PLAIN
Use the following options to define the format and schema registry:
format = avroconfluent_schema_registry = "https://{API KEY}:{URL-ENCODED SCHEMA REGISTRY SECRET KEY}@{SCHEMA REGISTRY URL}:443". Note that the schema registry uses basic authentication, which means that the URL's format is different from the Kafka URL.Tip:Use the
timeout={duration}query parameter (duration string) in your Confluent Schema Registry URI to change the default timeout for contacting the schema registry. By default, the timeout is 30 seconds.To form the URL, you need the following:
Any other options you need to configure your changefeed. See Options for a list of all available Enterprise changefeed options.
Step 9. Verify the output
Move to the terminal window in which you started the Kafka consumer. As the changefeed runs, you will see the change data messages similar to the following:
. . .
{"after":{"users":{"name":{"string":"Michael Clark"},"address":{"string":"85957 Ashley Junctions"},"credit_card":{"string":"4144089313"},"id":{"string":"d84cf3b6-7029-4d4d-aa81-e5caa9cce09e"},"city":{"string":"seattle"}}},"updated":{"string":"1659643584586630201.0000000000"}}
{"after":{"users":{"address":{"string":"17068 Christopher Isle"},"credit_card":{"string":"6664835435"},"id":{"string":"11b99275-92ce-4244-be61-4dae21973f87"},"city":{"string":"amsterdam"},"name":{"string":"John Soto"}}},"updated":{"string":"1659643585384406152.0000000000"}}
{"after":{"users":{"id":{"string":"a4666991-0292-4b00-8df0-d807c10eded5"},"city":{"string":"boston"},"name":{"string":"Anthony Snow"},"address":{"string":"74151 Carrillo Ramp"},"credit_card":{"string":"2630730025"}}},"updated":{"string":"1659643584990243411.0000000000"}}
{"updated":{"string":"1659643584877025654.0000000000"},"after":{"users":{"city":{"string":"seattle"},"name":{"string":"Tanya Holmes"},"address":{"string":"19023 Murphy Mall Apt. 79"},"credit_card":{"string":"6549598808"},"id":{"string":"434d4827-945f-4c7a-8d10-05c03e3bbeeb"}}}}
. . .
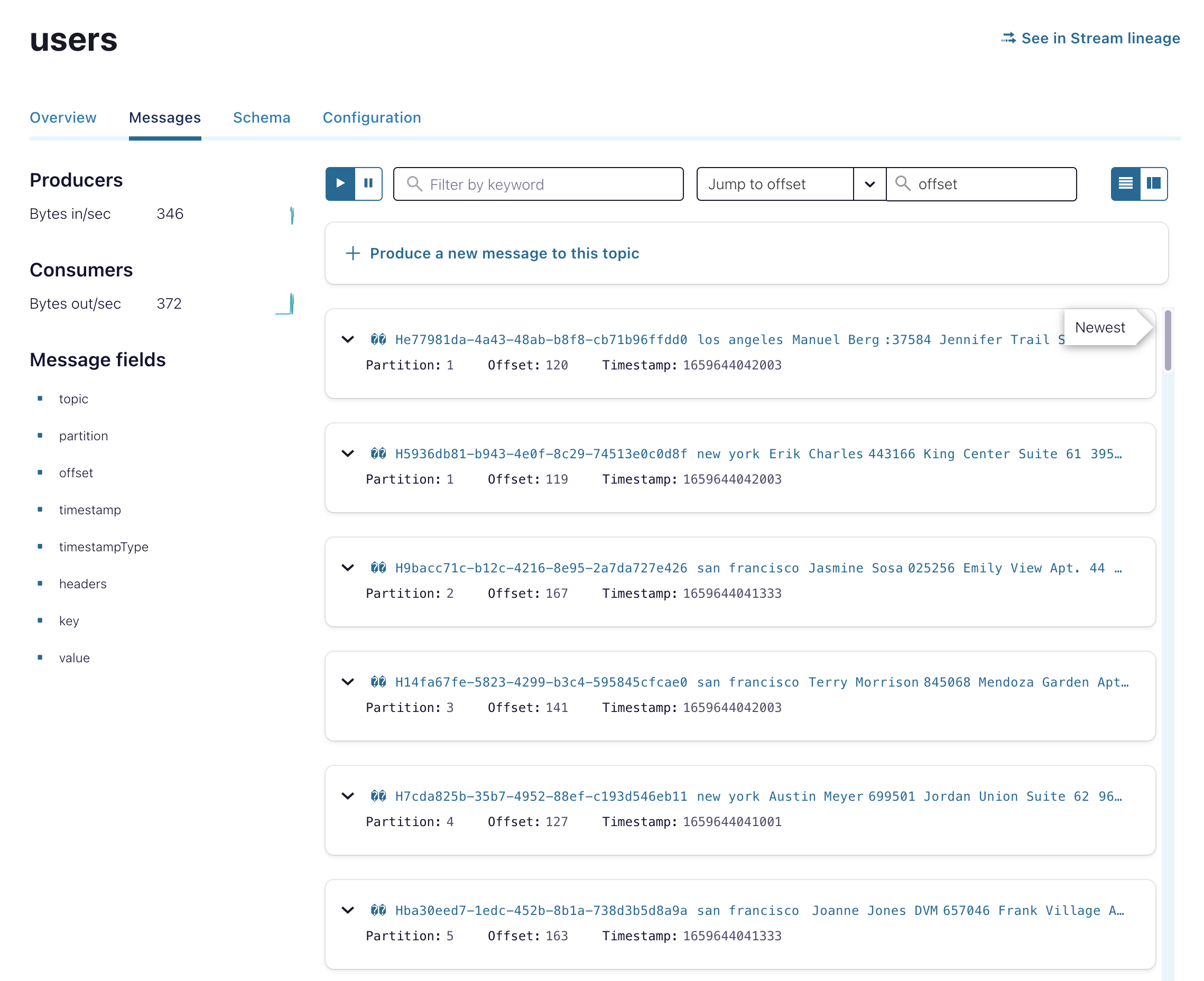
You can also view the messages for your cluster in the Confluent Cloud console in the Topics sidebar under the Messages tab.
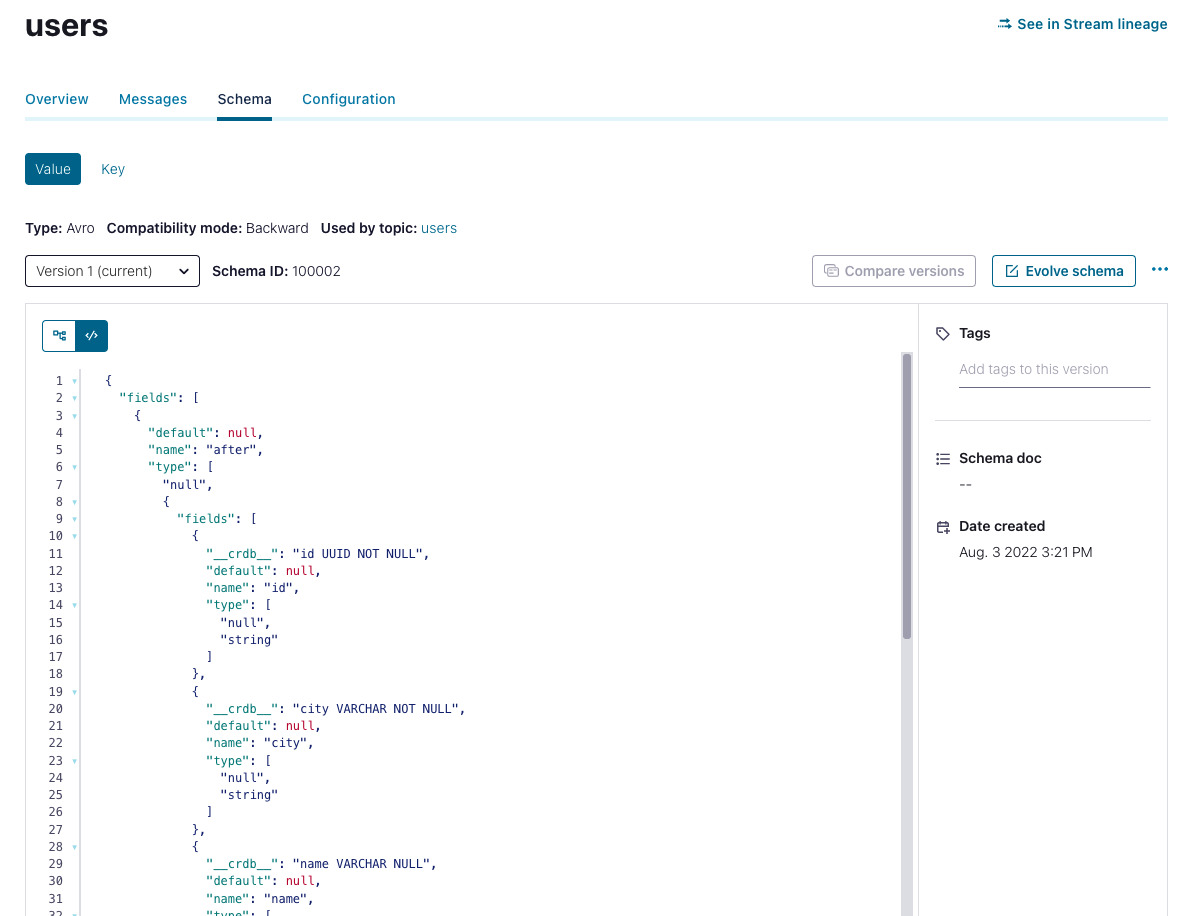
You can use the Schema tab to view the schema for a specific topic.
See also
Was this helpful?