
This page provides recipes for fixing performance issues in your applications.
Problems
This section describes how to use CockroachDB commands and dashboards to identify performance problems in your applications.
| Observation | Diagnosis | Solution |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Solutions
This section provides solutions for common performance issues in your applications.
Transaction contention
Transaction contention occurs when transactions issued from multiple clients at the same time operate on the same data. This can cause transactions to wait on each other (like when many people try to check out with the same cashier at a store) and decrease performance.
Indicators that your application is experiencing transaction contention
- In the Transaction Executions view on the Insights page, transaction executions display the High Contention insight.
- Your application is experiencing degraded performance with transaction errors like
SQLSTATE: 40001,RETRY_WRITE_TOO_OLD, andRETRY_SERIALIZABLE. See Transaction Retry Error Reference. - The SQL Statement Contention graph is showing spikes over time.
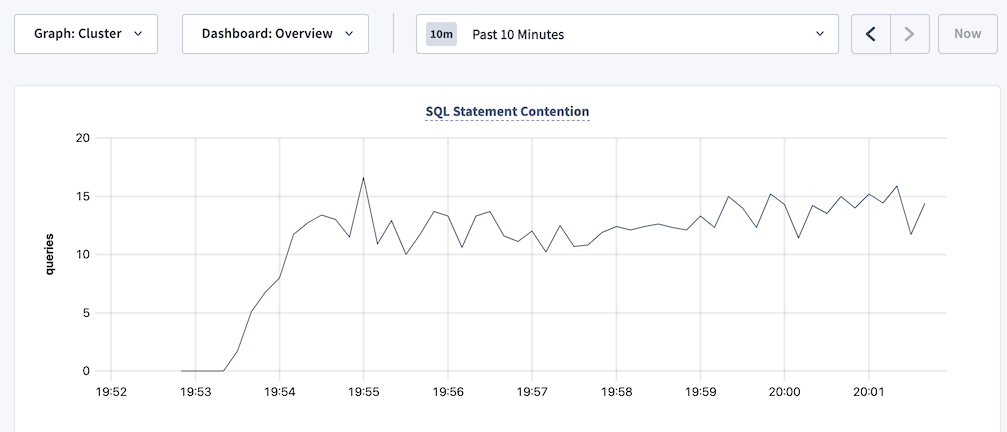
- The Transaction Restarts graph is showing spikes in retries over time.
Fix transaction contention problems
Find the transactions and statements within the transactions that are experiencing contention. CockroachDB has several tools to help you track down such transactions and statements:
- In the DB Console:
- Visit the Transaction Executions view on the Insights page and look for transaction executions with the High Contention insight.
- Visit the Transactions and Statements pages and sort transactions and statements by Contention Time.
Query the following tables:
crdb_internal.cluster_contended_indexesandcrdb_internal.cluster_contended_tablestables for your database to find the indexes and tables that are experiencing contention.crdb_internal.cluster_locksto find out which transactions are holding locks on which objects.crdb_internal.cluster_contention_eventsto view the tables/indexes with the most time under contention.
After you identify the transactions or statements that are causing contention, follow the steps in the next section to avoid contention.
If you experience a hanging or stuck query that is not showing up in the list of contended transactions and statements on the Transactions or Statements pages in the DB Console, the process described above will not work. You will need to follow the process described in Hanging or stuck queries instead.
Statements with full table scans
Full table scans often result in poor statement performance.
Indicators that your application has statements with full table scans
The following query returns statements with full table scans in their statement plan:
SHOW FULL TABLE SCANS;The following query against the
crdb_internal.node_statement_statisticstable returns results:SELECT count(*) as total_full_scans FROM crdb_internal.node_statement_statistics WHERE full_scan = true;Viewing the statement plan on the Statement Fingerprint page in the DB Console indicates that the plan contains full table scans.
The statement plans returned by the
EXPLAINandEXPLAIN ANALYZEcommands indicate that there are full table scans.The Full Table/Index Scans graph in the DB Console is showing spikes over time.
Fix full table scans in statements
Not every full table scan is an indicator of poor performance. The cost-based optimizer may decide on a full table scan when other index or join scans would result in longer execution time.
Examine the statements that result in full table scans and consider adding secondary indexes.
In the DB Console, visit the Schema Insights tab on the Insights page and check if there are any insights to create missing indexes. These missing index recommendations are generated based on slow statement execution. A missing index may cause a statement to have a suboptimal plan. If the execution was slow, based on the insights threshold, then it's likely the create index recommendation is valid. If the plan had a full table scan, it's likely that it should be removed with an index.
Also see Table scans best practices.
Suboptimal primary keys
Indicators that your tables are using suboptimal primary keys
- The Hardware metrics dashboard in the DB Console shows high resource usage per node.
- The Problem Ranges report on the Advanced Debug page in the DB Console indicates a high number of queries per second on a subset of ranges or nodes.
Fix suboptimal primary keys
Evaluate the schema of your table to see if you can redistribute data more evenly across multiple ranges. Specifically, make sure you have followed best practices when selecting your primary key.
If your application with a small dataset (for example, a dataset that contains few index key values) is experiencing resource contention, consider splitting your tables and indexes to distribute ranges across multiple nodes to reduce resource contention.
Slow writes
Indicators that your tables are experiencing slow writes
If the Overview dashboard in the DB Console shows high service latency when the QPS of INSERT and UPDATE statements is high, your tables are experiencing slow writes.
Fix slow writes
Secondary indexes can improve application read performance. However, there is overhead in maintaining secondary indexes that can affect your write performance. You should profile your tables periodically to determine whether an index is worth the overhead. To identify infrequently accessed indexes that could be candidates to drop, do one of the following:
- In the DB Console, visit the Schema Insights tab on the Insights page and check if there are any insights to drop unused indexes.
- In the DB Console, visit the Databases page and check databases and tables for Index Recommendations to drop unused indexes.
Run a join query against the
crdb_internal.index_usage_statisticsandcrdb_internal.table_indexestables:SELECT ti.descriptor_name as table_name, ti.index_name, total_reads, last_read FROM crdb_internal.index_usage_statistics AS us JOIN crdb_internal.table_indexes ti ON us.index_id = ti.index_id AND us.table_id = ti.descriptor_id ORDER BY total_reads ASC;table_name | index_name | total_reads | last_read -----------------------------+-----------------------------------------------+-------------+-------------------------------- vehicle_location_histories | vehicle_location_histories_pkey | 1 | 2021-09-28 22:59:03.324398+00 rides | rides_auto_index_fk_city_ref_users | 1 | 2021-09-28 22:59:01.500962+00 rides | rides_auto_index_fk_vehicle_city_ref_vehicles | 1 | 2021-09-28 22:59:02.470526+00 user_promo_codes | user_promo_codes_pkey | 456 | 2021-09-29 00:01:17.063418+00 promo_codes | promo_codes_pkey | 910 | 2021-09-29 00:01:17.062319+00 vehicles | vehicles_pkey | 3591 | 2021-09-29 00:01:18.261658+00 users | users_pkey | 5401 | 2021-09-29 00:01:18.260198+00 rides | rides_pkey | 45658 | 2021-09-29 00:01:18.258208+00 vehicles | vehicles_auto_index_fk_city_ref_users | 87119 | 2021-09-29 00:01:19.071476+00 (9 rows)Use the values in the
total_readsandlast_readcolumns to identify indexes that have low usage or are stale and can be dropped.
Too many MVCC values
Indicators that your tables have too many MVCC values
In the Databases page in the DB Console, the Tables view shows the percentage of live data for each table. For example:
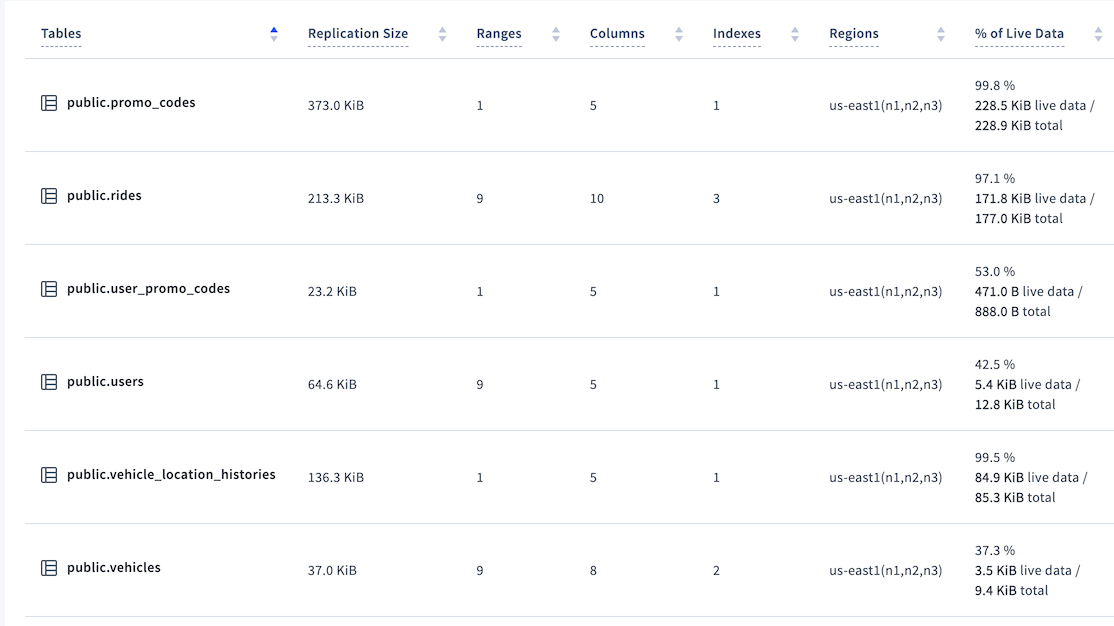
In this example, at 37.3% the vehicles table would be considered to have a low percentage of live data. In the worst cases, the percentage can be 0%.
A low percentage of live data can cause statements to scan more data (MVCC values) than required, which can reduce performance.
Configure CockroachDB to purge MVCC values
Reduce the gc.ttlseconds zone configuration of the table as much as possible.
See also
If you aren't sure whether SQL query performance needs to be improved, see Identify slow queries.
Was this helpful?