
This tutorial shows you essential techniques for getting fast reads and writes in CockroachDB, starting with a single-region deployment and expanding into multiple regions.
For a comprehensive list of tuning recommendations, only some of which are demonstrated here, see SQL Performance Best Practices.
Overview
Topology
You'll start with a 3-node CockroachDB cluster in a single Google Compute Engine (GCE) zone, with an extra instance for running a client application workload:
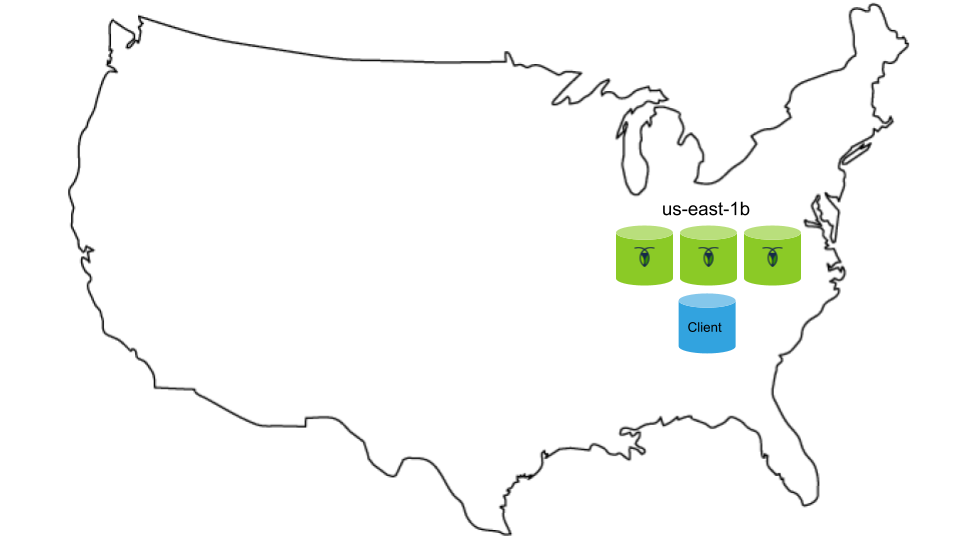
Within a single GCE zone, network latency between instances should be sub-millisecond.
You'll then scale the cluster to 9 nodes running across 3 GCE regions, with an extra instance in each region for a client application workload:
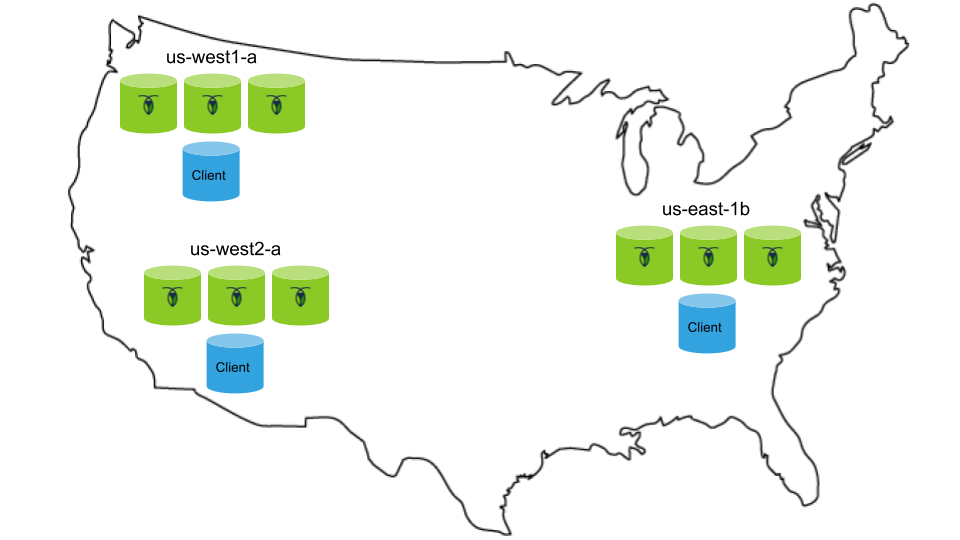
To reproduce the performance demonstrated in this tutorial:
- For each CockroachDB node, you'll use the
n1-standard-4machine type (4 vCPUs, 15 GB memory) with the Ubuntu 16.04 OS image and a local SSD disk. - For running the client application workload, you'll use smaller instances, such as
n1-standard-1.
Schema
Your schema and data will be based on our open-source, fictional peer-to-peer ride-sharing application,MovR.
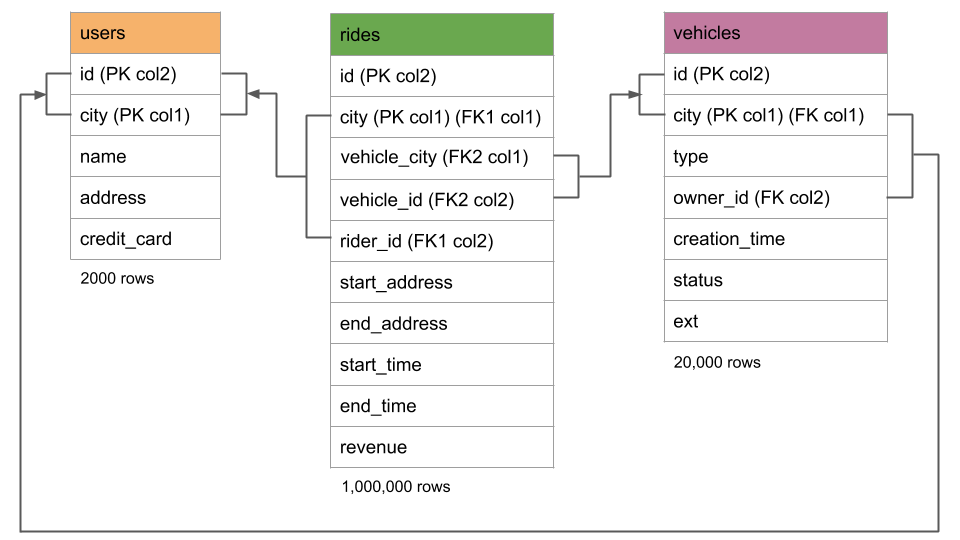
A few notes about the schema:
- There are just three self-explanatory tables: In essence,
usersrepresents the people registered for the service,vehiclesrepresents the pool of vehicles for the service, andridesrepresents when and where users have participated. - Each table has a composite primary key, with
citybeing first in the key. Although not necessary initially in the single-region deployment, once you scale the cluster to multiple regions, these compound primary keys will enable you to geo-partition data at the row level bycity. As such, this tutorial demonstrates a schema designed for future scaling. - The
IMPORTfeature you'll use to import the data does not support foreign keys, so you'll import the data without foreign key constraints. However, the import will create the secondary indexes required to add the foreign keys later. - The
ridestable contains bothcityand the seemingly redundantvehicle_city. This redundancy is necessary because, while it is not possible to apply more than one foreign key constraint to a single column, you will need to apply two foreign key constraints to theridestable, and each will require city as part of the constraint. The duplicatevehicle_city, which is kept in sync withcityvia aCHECKconstraint, lets you overcome this limitation.
Important concepts
To understand the techniques in this tutorial, and to be able to apply them in your own scenarios, it's important to first understand how reads and writes work in CockroachDB. Review that document before getting started here.
Single-region deployment
Step 1. Configure your network
CockroachDB requires TCP communication on two ports:
- 26257 (
tcp:26257) for inter-node communication (i.e., working as a cluster) - 8080 (
tcp:8080) for accessing the Web UI
Since GCE instances communicate on their internal IP addresses by default, you do not need to take any action to enable inter-node communication. However, if you want to access the Web UI from your local network, you must create a firewall rule for your project:
| Field | Recommended Value |
|---|---|
| Name | cockroachweb |
| Source filter | IP ranges |
| Source IP ranges | Your local network's IP ranges |
| Allowed protocols | tcp:8080 |
| Target tags | cockroachdb |
The tag feature will let you easily apply the rule to your instances.
Step 2. Create instances
You'll start with a 3-node CockroachDB cluster in the us-east1-b GCE zone, with an extra instance for running a client application workload.
Create 3 instances for your CockroachDB nodes. While creating each instance:
- Select the
us-east1-bzone. - Use the
n1-standard-4machine type (4 vCPUs, 15 GB memory). - Use the Ubuntu 16.04 OS image.
- Create and mount a local SSD.
- To apply the Web UI firewall rule you created earlier, click Management, disk, networking, SSH keys, select the Networking tab, and then enter
cockroachdbin the Network tags field.
- Select the
Note the internal IP address of each
n1-standard-4instance. You'll need these addresses when starting the CockroachDB nodes.Create a separate instance for running a client application workload, also in the
us-east1-bzone. This instance can be smaller, such asn1-standard-1.
Step 3. Start a 3-node cluster
Start the nodes
SSH to the first
n1-standard-4instance.Download the CockroachDB archive for Linux, extract the binary, and copy it into the
PATH:$ curl https://binaries.cockroachdb.com/cockroach-v2.1.11.linux-amd64.tgz \ | tar -xz$ sudo cp -i cockroach-v2.1.11.linux-amd64/cockroach /usr/local/bin/Run the
cockroach startcommand:$ cockroach start \ --insecure \ --advertise-host=<node1 internal address> \ --join=<node1 internal address>:26257,<node2 internal address>:26257,<node3 internal address>:26257 \ --locality=cloud=gce,region=us-east1,zone=us-east1-b \ --cache=.25 \ --max-sql-memory=.25 \ --backgroundRepeat steps 1 - 3 for the other two
n1-standard-4instances. Be sure to adjust the--advertise-addrflag each time.
Initialize the cluster
SSH to the fourth instance, the one not running a CockroachDB node.
Download the CockroachDB archive for Linux, and extract the binary:
$ curl https://binaries.cockroachdb.com/cockroach-v2.1.11.linux-amd64.tgz \ | tar -xzCopy the binary into the
PATH:$ sudo cp -i cockroach-v2.1.11.linux-amd64/cockroach /usr/local/bin/Run the
cockroach initcommand:$ cockroach init --insecure --host=<address of any node>Each node then prints helpful details to the standard output, such as the CockroachDB version, the URL for the Web UI, and the SQL URL for clients.
Step 4. Import the Movr dataset
Now you'll import Movr data representing users, vehicles, and rides in 3 eastern US cities (New York, Boston, and Washington DC) and 3 western US cities (Los Angeles, San Francisco, and Seattle).
Still on the fourth instance, start the built-in SQL shell, pointing it at one of the CockroachDB nodes:
$ cockroach sql --insecure --host=<address of any node>Create the
movrdatabase and set it as the default:> CREATE DATABASE movr;> SET DATABASE = movr;Use the
IMPORTstatement to create and populate theusers,vehicles,andridestables:> IMPORT TABLE users ( id UUID NOT NULL, city STRING NOT NULL, name STRING NULL, address STRING NULL, credit_card STRING NULL, CONSTRAINT "primary" PRIMARY KEY (city ASC, id ASC) ) CSV DATA ( 'https://s3-us-west-1.amazonaws.com/cockroachdb-movr/datasets/perf-tuning/users/n1.0.csv' );job_id | status | fraction_completed | rows | index_entries | system_records | bytes +--------------------+-----------+--------------------+------+---------------+----------------+--------+ 390345990764396545 | succeeded | 1 | 1998 | 0 | 0 | 241052 (1 row) Time: 2.882582355s> IMPORT TABLE vehicles ( id UUID NOT NULL, city STRING NOT NULL, type STRING NULL, owner_id UUID NULL, creation_time TIMESTAMP NULL, status STRING NULL, ext JSON NULL, mycol STRING NULL, CONSTRAINT "primary" PRIMARY KEY (city ASC, id ASC), INDEX vehicles_auto_index_fk_city_ref_users (city ASC, owner_id ASC) ) CSV DATA ( 'https://s3-us-west-1.amazonaws.com/cockroachdb-movr/datasets/perf-tuning/vehicles/n1.0.csv' );job_id | status | fraction_completed | rows | index_entries | system_records | bytes +--------------------+-----------+--------------------+-------+---------------+----------------+---------+ 390346109887250433 | succeeded | 1 | 19998 | 19998 | 0 | 3558767 (1 row) Time: 5.803841493s> IMPORT TABLE rides ( id UUID NOT NULL, city STRING NOT NULL, vehicle_city STRING NULL, rider_id UUID NULL, vehicle_id UUID NULL, start_address STRING NULL, end_address STRING NULL, start_time TIMESTAMP NULL, end_time TIMESTAMP NULL, revenue DECIMAL(10,2) NULL, CONSTRAINT "primary" PRIMARY KEY (city ASC, id ASC), INDEX rides_auto_index_fk_city_ref_users (city ASC, rider_id ASC), INDEX rides_auto_index_fk_vehicle_city_ref_vehicles (vehicle_city ASC, vehicle_id ASC), CONSTRAINT check_vehicle_city_city CHECK (vehicle_city = city) ) CSV DATA ( 'https://s3-us-west-1.amazonaws.com/cockroachdb-movr/datasets/perf-tuning/rides/n1.0.csv', 'https://s3-us-west-1.amazonaws.com/cockroachdb-movr/datasets/perf-tuning/rides/n1.1.csv', 'https://s3-us-west-1.amazonaws.com/cockroachdb-movr/datasets/perf-tuning/rides/n1.2.csv', 'https://s3-us-west-1.amazonaws.com/cockroachdb-movr/datasets/perf-tuning/rides/n1.3.csv', 'https://s3-us-west-1.amazonaws.com/cockroachdb-movr/datasets/perf-tuning/rides/n1.4.csv', 'https://s3-us-west-1.amazonaws.com/cockroachdb-movr/datasets/perf-tuning/rides/n1.5.csv', 'https://s3-us-west-1.amazonaws.com/cockroachdb-movr/datasets/perf-tuning/rides/n1.6.csv', 'https://s3-us-west-1.amazonaws.com/cockroachdb-movr/datasets/perf-tuning/rides/n1.7.csv', 'https://s3-us-west-1.amazonaws.com/cockroachdb-movr/datasets/perf-tuning/rides/n1.8.csv', 'https://s3-us-west-1.amazonaws.com/cockroachdb-movr/datasets/perf-tuning/rides/n1.9.csv' );job_id | status | fraction_completed | rows | index_entries | system_records | bytes +--------------------+-----------+--------------------+--------+---------------+----------------+-----------+ 390346325693792257 | succeeded | 1 | 999996 | 1999992 | 0 | 339741841 (1 row) Time: 44.620371424sTip:You can observe the progress of imports as well as all schema change operations (e.g., adding secondary indexes) on the Jobs page of the Web UI.
Logically, there should be a number of foreign key relationships between the tables:
Referencing columns Referenced columns vehicles.city,vehicles.owner_idusers.city,users.idrides.city,rides.rider_idusers.city,users.idrides.vehicle_city,rides.vehicle_idvehicles.city,vehicles.idAs mentioned earlier, it wasn't possible to put these relationships in place during
IMPORT, but it was possible to create the required secondary indexes. Now, let's add the foreign key constraints:> ALTER TABLE vehicles ADD CONSTRAINT fk_city_ref_users FOREIGN KEY (city, owner_id) REFERENCES users (city, id);> ALTER TABLE rides ADD CONSTRAINT fk_city_ref_users FOREIGN KEY (city, rider_id) REFERENCES users (city, id);> ALTER TABLE rides ADD CONSTRAINT fk_vehicle_city_ref_vehicles FOREIGN KEY (vehicle_city, vehicle_id) REFERENCES vehicles (city, id);Exit the built-in SQL shell:
> \q
Step 5. Install the Python client
When measuring SQL performance, it's best to run a given statement multiple times and look at the average and/or cumulative latency. For that purpose, you'll install and use a Python testing client.
Still on the fourth instance, make sure all of the system software is up-to-date:
$ sudo apt-get update && sudo apt-get -y upgradeInstall the
psycopg2driver:$ sudo apt-get install python-psycopg2Download the Python client:
$ wget https://raw.githubusercontent.com/cockroachdb/docs/master/_includes/v2.1/performance/tuning.py \ && chmod +x tuning.pyAs you'll see below, this client lets you pass command-line flags:
Flag Description --hostThe IP address of the target node. This is used in the client's connection string. --statementThe SQL statement to execute. --repeatThe number of times to repeat the statement. This defaults to 20. When run, the client prints the median time in seconds across all repetitions of the statement. Optionally, you can pass two other flags,
--timeto print the execution time in seconds for each repetition of the statement, and--cumulativeto print the cumulative time in seconds for all repetitions.--cumulativeis particularly useful when testing writes.Tip:To get similar help directly in your shell, use
./tuning.py --help.
Step 6. Test/tune read performance
- Filtering by the primary key
- Filtering by a non-indexed column (full table scan)
- Filtering by a secondary index
- Filtering by a secondary index storing additional columns
- Joining data from different tables
- Using
IN (list)with a subquery - Using
IN (list)with explicit values
Filtering by the primary key
Retrieving a single row based on the primary key will usually return in 2ms or less:
$ ./tuning.py \
--host=<address of any node> \
--statement="SELECT * FROM rides WHERE city = 'boston' AND id = '000007ef-fa0f-4a6e-a089-ce74aa8d2276'" \
--repeat=50 \
--times
Result:
['id', 'city', 'vehicle_city', 'rider_id', 'vehicle_id', 'start_address', 'end_address', 'start_time', 'end_time', 'revenue']
['000007ef-fa0f-4a6e-a089-ce74aa8d2276', 'boston', 'boston', 'd66c386d-4b7b-48a7-93e6-f92b5e7916ab', '6628bbbc-00be-4891-bc00-c49f2f16a30b', '4081 Conner Courts\nSouth Taylor, VA 86921', '2808 Willis Wells Apt. 931\nMccoyberg, OH 10303-4879', '2018-07-20 01:46:46.003070', '2018-07-20 02:27:46.003070', '44.25']
Times (milliseconds):
[2.1638870239257812, 1.2159347534179688, 1.0809898376464844, 1.0669231414794922, 1.2650489807128906, 1.1401176452636719, 1.1310577392578125, 1.0380744934082031, 1.199960708618164, 1.0530948638916016, 1.1000633239746094, 1.3430118560791016, 1.104116439819336, 1.0750293731689453, 1.0609626770019531, 1.088857650756836, 1.1639595031738281, 1.2559890747070312, 1.1899471282958984, 1.0449886322021484, 1.1057853698730469, 1.127004623413086, 0.9729862213134766, 1.1131763458251953, 1.0879039764404297, 1.119852066040039, 1.065969467163086, 1.0371208190917969, 1.1181831359863281, 1.0409355163574219, 1.0859966278076172, 1.1398792266845703, 1.032114028930664, 1.1000633239746094, 1.1360645294189453, 1.146078109741211, 1.329183578491211, 1.1131763458251953, 1.1548995971679688, 0.9977817535400391, 1.1138916015625, 1.085042953491211, 1.0950565338134766, 1.0869503021240234, 1.0170936584472656, 1.0571479797363281, 1.0640621185302734, 1.1110305786132812, 1.1279582977294922, 1.1119842529296875]
Median time (milliseconds):
1.10495090485
Retrieving a subset of columns will usually be even faster:
$ ./tuning.py \
--host=<address of any node> \
--statement="SELECT rider_id, vehicle_id \
FROM rides \
WHERE city = 'boston' AND id = '000007ef-fa0f-4a6e-a089-ce74aa8d2276'" \
--repeat=50 \
--times
Result:
['rider_id', 'vehicle_id']
['d66c386d-4b7b-48a7-93e6-f92b5e7916ab', '6628bbbc-00be-4891-bc00-c49f2f16a30b']
Times (milliseconds):
[2.218961715698242, 1.2569427490234375, 1.3570785522460938, 1.1570453643798828, 1.3251304626464844, 1.3320446014404297, 1.0790824890136719, 1.0139942169189453, 1.0251998901367188, 1.1150836944580078, 1.1949539184570312, 1.2140274047851562, 1.2080669403076172, 1.238107681274414, 1.071929931640625, 1.104116439819336, 1.0230541229248047, 1.0571479797363281, 1.0519027709960938, 1.0688304901123047, 1.0118484497070312, 1.0051727294921875, 1.1889934539794922, 1.0571479797363281, 1.177072525024414, 1.0449886322021484, 1.0669231414794922, 1.004934310913086, 0.9818077087402344, 0.9369850158691406, 1.004934310913086, 1.0461807250976562, 1.0628700256347656, 1.1332035064697266, 1.1780261993408203, 1.0361671447753906, 1.1410713195800781, 1.1188983917236328, 1.026153564453125, 0.9629726409912109, 1.0199546813964844, 1.0409355163574219, 1.0440349578857422, 1.1110305786132812, 1.1761188507080078, 1.508951187133789, 1.2068748474121094, 1.3430118560791016, 1.4159679412841797, 1.3141632080078125]
Median time (milliseconds):
1.09159946442
Filtering by a non-indexed column (full table scan)
You'll get generally poor performance when retrieving a single row based on a column that is not in the primary key or any secondary index:
$ ./tuning.py \
--host=<address of any node> \
--statement="SELECT * FROM users WHERE name = 'Natalie Cunningham'" \
--repeat=50 \
--times
Result:
['id', 'city', 'name', 'address', 'credit_card']
['02cc9e5b-1e91-4cdb-87c4-726b4ea7219a', 'boston', 'Natalie Cunningham', '97477 Lee Path\nKimberlyport, CA 65960', '4532613656695680']
Times (milliseconds):
[33.271074295043945, 4.4689178466796875, 4.18400764465332, 4.327058792114258, 5.700111389160156, 4.509925842285156, 4.525899887084961, 4.294157028198242, 4.516124725341797, 5.700111389160156, 5.105018615722656, 4.5070648193359375, 4.798173904418945, 5.930900573730469, 4.445075988769531, 4.1790008544921875, 4.065036773681641, 4.296064376831055, 5.722999572753906, 4.827976226806641, 4.640102386474609, 4.374980926513672, 4.269123077392578, 4.422903060913086, 4.110813140869141, 4.091024398803711, 4.189014434814453, 4.345178604125977, 5.600929260253906, 4.827976226806641, 4.416942596435547, 4.424095153808594, 4.736185073852539, 4.462003707885742, 4.307031631469727, 5.10096549987793, 4.56690788269043, 4.641056060791016, 4.701137542724609, 4.538059234619141, 4.474163055419922, 4.561901092529297, 4.431009292602539, 4.756927490234375, 4.54401969909668, 4.415035247802734, 4.396915435791016, 5.9719085693359375, 4.543066024780273, 5.830049514770508]
Median time (milliseconds):
4.51302528381
To understand why this query performs poorly, use the SQL client built into the cockroach binary to EXPLAIN the query plan:
$ cockroach sql \
--insecure \
--host=<address of any node> \
--database=movr \
--execute="EXPLAIN SELECT * FROM users WHERE name = 'Natalie Cunningham';"
tree | field | description
+------+-------+---------------+
scan | |
| table | users@primary
| spans | ALL
(3 rows)
The row with spans | ALL shows you that, without a secondary index on the name column, CockroachDB scans every row of the users table, ordered by the primary key (city/id), until it finds the row with the correct name value.
Filtering by a secondary index
To speed up this query, add a secondary index on name:
$ cockroach sql \
--insecure \
--host=<address of any node> \
--database=movr \
--execute="CREATE INDEX on users (name);"
The query will now return much faster:
$ ./tuning.py \
--host=<address of any node> \
--statement="SELECT * FROM users WHERE name = 'Natalie Cunningham'" \
--repeat=50 \
--times
Result:
['id', 'city', 'name', 'address', 'credit_card']
['02cc9e5b-1e91-4cdb-87c4-726b4ea7219a', 'boston', 'Natalie Cunningham', '97477 Lee Path\nKimberlyport, CA 65960', '4532613656695680']
Times (milliseconds):
[3.545045852661133, 1.4619827270507812, 1.399993896484375, 2.0101070404052734, 1.672983169555664, 1.4941692352294922, 1.4650821685791016, 1.4579296112060547, 1.567840576171875, 1.5709400177001953, 1.4760494232177734, 1.6181468963623047, 1.6210079193115234, 1.6970634460449219, 1.6469955444335938, 1.7261505126953125, 1.7559528350830078, 1.875162124633789, 1.7170906066894531, 1.870870590209961, 1.641988754272461, 1.7061233520507812, 1.628875732421875, 1.6558170318603516, 1.7809867858886719, 1.6698837280273438, 1.8429756164550781, 1.6090869903564453, 1.7080307006835938, 1.74713134765625, 1.6620159149169922, 1.9519329071044922, 1.6849040985107422, 1.7440319061279297, 1.8851757049560547, 1.8699169158935547, 1.7409324645996094, 1.9140243530273438, 1.7828941345214844, 1.7158985137939453, 1.6720294952392578, 1.7750263214111328, 1.7368793487548828, 1.9288063049316406, 1.8749237060546875, 1.7838478088378906, 1.8091201782226562, 1.8210411071777344, 1.7669200897216797, 1.8210411071777344]
Median time (milliseconds):
1.72162055969
To understand why performance improved from 4.51ms (without index) to 1.72ms (with index), use EXPLAIN to see the new query plan:
$ cockroach sql \
--insecure \
--host=<address of any node> \
--database=movr \
--execute="EXPLAIN SELECT * FROM users WHERE name = 'Natalie Cunningham';"
tree | field | description
+------------+-------+-------------------------------------------------------+
index-join | |
├── scan | |
│ | table | users@users_name_idx
│ | spans | /"Natalie Cunningham"-/"Natalie Cunningham"/PrefixEnd
└── scan | |
| table | users@primary
(6 rows)
This shows you that CockroachDB starts with the secondary index (table | users@users_name_idx). Because it is sorted by name, the query can jump directly to the relevant value (spans | /"Natalie Cunningham"-/"Natalie Cunningham"/PrefixEnd). However, the query needs to return values not in the secondary index, so CockroachDB grabs the primary key (city/id) stored with the name value (the primary key is always stored with entries in a secondary index), jumps to that value in the primary index, and then returns the full row.
Thinking back to the earlier discussion of ranges and leaseholders, because the users table is small (under 64 MiB), the primary index and all secondary indexes are contained in a single range with a single leaseholder. If the table were bigger, however, the primary index and secondary index could reside in separate ranges, each with its own leaseholder. In this case, if the leaseholders were on different nodes, the query would require more network hops, further increasing latency.
Filtering by a secondary index storing additional columns
When you have a query that filters by a specific column but retrieves a subset of the table's total columns, you can improve performance by storing those additional columns in the secondary index to prevent the query from needing to scan the primary index as well.
For example, let's say you frequently retrieve a user's name and credit card number:
$ ./tuning.py \
--host=<address of any node> \
--statement="SELECT name, credit_card FROM users WHERE name = 'Natalie Cunningham'" \
--repeat=50 \
--times
Result:
['name', 'credit_card']
['Natalie Cunningham', '4532613656695680']
Times (milliseconds):
[2.8769969940185547, 1.7559528350830078, 1.8100738525390625, 1.8839836120605469, 1.5971660614013672, 1.5900135040283203, 1.7750263214111328, 2.2847652435302734, 1.641988754272461, 1.4967918395996094, 1.4641284942626953, 1.6689300537109375, 1.9679069519042969, 1.8970966339111328, 1.8780231475830078, 1.7609596252441406, 1.68609619140625, 1.9791126251220703, 1.661062240600586, 1.9869804382324219, 1.5938282012939453, 1.8041133880615234, 1.5909671783447266, 1.5878677368164062, 1.7380714416503906, 1.638174057006836, 1.6970634460449219, 1.9309520721435547, 1.992940902709961, 1.8689632415771484, 1.7511844635009766, 2.007007598876953, 1.9829273223876953, 1.8939971923828125, 1.7490386962890625, 1.6179084777832031, 1.6510486602783203, 1.6078948974609375, 1.6129016876220703, 1.67083740234375, 1.786947250366211, 1.7840862274169922, 1.956939697265625, 1.8689632415771484, 1.9350051879882812, 1.789093017578125, 1.9249916076660156, 1.8649101257324219, 1.9619464874267578, 1.7361640930175781]
Median time (milliseconds):
1.77955627441
With the current secondary index on name, CockroachDB still needs to scan the primary index to get the credit card number:
$ cockroach sql \
--insecure \
--host=<address of any node> \
--database=movr \
--execute="EXPLAIN SELECT name, credit_card FROM users WHERE name = 'Natalie Cunningham';"
tree | field | description
+------------+-------+-------------------------------------------------------+
index-join | |
├── scan | |
│ | table | users@users_name_idx
│ | spans | /"Natalie Cunningham"-/"Natalie Cunningham"/PrefixEnd
└── scan | |
| table | users@primary
(6 rows)
Let's drop and recreate the index on name, this time storing the credit_card value in the index:
$ cockroach sql \
--insecure \
--host=<address of any node> \
--database=movr \
--execute="DROP INDEX users_name_idx;"
$ cockroach sql \
--insecure \
--host=<address of any node> \
--database=movr \
--execute="CREATE INDEX ON users (name) STORING (credit_card);"
Now that credit_card values are stored in the index on name, CockroachDB only needs to scan that index:
$ cockroach sql \
--insecure \
--host=<address of any node> \
--database=movr \
--execute="EXPLAIN SELECT name, credit_card FROM users WHERE name = 'Natalie Cunningham';"
tree | field | description
+------+-------+-------------------------------------------------------+
scan | |
| table | users@users_name_idx
| spans | /"Natalie Cunningham"-/"Natalie Cunningham"/PrefixEnd
(3 rows)
This results in even faster performance, reducing latency from 1.77ms (index without storing) to 0.99ms (index with storing):
$ ./tuning.py \
--host=<address of any node> \
--statement="SELECT name, credit_card FROM users WHERE name = 'Natalie Cunningham'" \
--repeat=50 \
--times
Result:
['name', 'credit_card']
['Natalie Cunningham', '4532613656695680']
Times (milliseconds):
[1.8029212951660156, 0.9858608245849609, 0.9548664093017578, 0.8459091186523438, 0.9710788726806641, 1.1639595031738281, 0.8571147918701172, 0.8800029754638672, 0.8509159088134766, 0.8771419525146484, 1.1739730834960938, 0.9100437164306641, 1.1181831359863281, 0.9679794311523438, 1.0800361633300781, 1.02996826171875, 1.2090206146240234, 1.0440349578857422, 1.210927963256836, 1.0418891906738281, 1.1951923370361328, 0.9548664093017578, 1.0848045349121094, 0.9748935699462891, 1.15203857421875, 1.0280609130859375, 1.0819435119628906, 0.9641647338867188, 1.0979175567626953, 0.9720325469970703, 1.0638236999511719, 0.9410381317138672, 1.0039806365966797, 1.207113265991211, 0.9911060333251953, 1.0039806365966797, 0.9810924530029297, 0.9360313415527344, 0.9589195251464844, 1.0609626770019531, 0.9949207305908203, 1.0139942169189453, 0.9899139404296875, 0.9818077087402344, 0.9679794311523438, 0.8809566497802734, 0.9558200836181641, 0.8878707885742188, 1.0380744934082031, 0.8897781372070312]
Median time (milliseconds):
0.990509986877
Joining data from different tables
Secondary indexes are crucial when joining data from different tables as well.
For example, let's say you want to count the number of users who started rides on a given day. To do this, you need to use a join to get the relevant rides from the rides table and then map the rider_id for each of those rides to the corresponding id in the users table, counting each mapping only once:
$ ./tuning.py \
--host=<address of any node> \
--statement="SELECT count(DISTINCT users.id) \
FROM users \
INNER JOIN rides ON rides.rider_id = users.id \
WHERE start_time BETWEEN '2018-07-20 00:00:00' AND '2018-07-21 00:00:00'" \
--repeat=50 \
--times
Result:
['count']
['1998']
Times (milliseconds):
[1443.5458183288574, 1546.0000038146973, 1563.858985900879, 1530.3218364715576, 1574.7389793395996, 1572.7760791778564, 1566.4539337158203, 1595.655918121338, 1588.2930755615234, 1567.6488876342773, 1564.5530223846436, 1573.4570026397705, 1581.406831741333, 1587.864875793457, 1575.7901668548584, 1565.0341510772705, 1519.8209285736084, 1599.7698307037354, 1612.4188899993896, 1582.5250148773193, 1604.076862335205, 1596.8739986419678, 1569.6821212768555, 1583.7080478668213, 1549.9720573425293, 1563.5790824890137, 1555.6750297546387, 1577.6000022888184, 1582.3569297790527, 1568.8848495483398, 1580.854892730713, 1566.9701099395752, 1578.8500308990479, 1592.677116394043, 1549.3559837341309, 1561.805009841919, 1561.812162399292, 1543.4870719909668, 1523.3290195465088, 1583.9049816131592, 1565.9120082855225, 1575.1979351043701, 1581.1400413513184, 1616.6048049926758, 1602.9179096221924, 1583.8429927825928, 1570.2300071716309, 1573.2421875, 1558.588981628418, 1548.7489700317383]
Median time (milliseconds):
1573.00913334
To understand what's happening, use EXPLAIN to see the query plan:
$ cockroach sql \
--insecure \
--host=<address of any node> \
--database=movr \
--execute="EXPLAIN SELECT count(DISTINCT users.id) \
FROM users \
INNER JOIN rides ON rides.rider_id = users.id \
WHERE start_time BETWEEN '2018-07-20 00:00:00' AND '2018-07-21 00:00:00';"
tree | field | description
+---------------------+-------------+----------------------+
group | |
│ | aggregate 0 | count(DISTINCT id)
│ | scalar |
└── render | |
└── join | |
│ | type | inner
│ | equality | (id) = (rider_id)
├── scan | |
│ | table | users@users_name_idx
│ | spans | ALL
└── scan | |
| table | rides@primary
| spans | ALL
(13 rows)
Reading from bottom up, you can see that CockroachDB does a full table scan (spans | ALL) first on rides to get all rows with a start_time in the specified range and then does another full table scan on users to find matching rows and calculate the count.
Given that the rides table is large, its data is split across several ranges. Each range is replicated and has a leaseholder. At least some of these leaseholders are likely located on different nodes. This means that the full table scan of rides involves several network hops to various leaseholders before finally going to the leaseholder for users to do a full table scan there.
To track this specifically, let's use the SHOW EXPERIMENTAL_RANGES statement to find out where the relevant leaseholders reside for rides and users:
$ cockroach sql \
--insecure \
--host=<address of any node> \
--database=movr \
--execute="SHOW EXPERIMENTAL_RANGES FROM TABLE rides;"
start_key | end_key | range_id | replicas | lease_holder
+----------------------------------------------------------------------------+----------------------------------------------------------------------------+----------+----------+--------------+
NULL | /"boston"/"\xfe\xdd?\xbb4\xabOV\x84\x00M\x89#-a6"/PrefixEnd | 34 | {1,2,3} | 2
/"boston"/"\xfe\xdd?\xbb4\xabOV\x84\x00M\x89#-a6"/PrefixEnd | /"los angeles"/"<\x12\xe4\xce&\xfdH\u070f?)\xc7\xf92\a\x03" | 35 | {1,2,3} | 2
/"los angeles"/"<\x12\xe4\xce&\xfdH\u070f?)\xc7\xf92\a\x03" | /"new york"/"0\xa6p\x96\tmOԗ#\xaa\xb7\x90\x12\xe67"/PrefixEnd | 39 | {1,2,3} | 2
/"new york"/"0\xa6p\x96\tmOԗ#\xaa\xb7\x90\x12\xe67"/PrefixEnd | /"san francisco"/"(m*OM\x15J\xbc\xb6n\xaass\x10\xc4\xff"/PrefixEnd | 37 | {1,2,3} | 1
/"san francisco"/"(m*OM\x15J\xbc\xb6n\xaass\x10\xc4\xff"/PrefixEnd | /"seattle"/"\x17\xd24\a\xb5\xbdN\x9d\xa1\xd2Dθ^\xe1M"/PrefixEnd | 40 | {1,2,3} | 2
/"seattle"/"\x17\xd24\a\xb5\xbdN\x9d\xa1\xd2Dθ^\xe1M"/PrefixEnd | /"washington dc"/"\x135\xe5e\x15\xefNۊ\x10)\xba\x19\x04\xff\xdc"/PrefixEnd | 44 | {1,2,3} | 2
/"washington dc"/"\x135\xe5e\x15\xefNۊ\x10)\xba\x19\x04\xff\xdc"/PrefixEnd | NULL | 46 | {1,2,3} | 2
(7 rows)
$ cockroach sql \
--insecure \
--host=<address of any node> \
--database=movr \
--execute="SHOW EXPERIMENTAL_RANGES FROM TABLE users;"
start_key | end_key | range_id | replicas | lease_holder
+-----------+---------+----------+----------+--------------+
NULL | NULL | 49 | {1,2,3} | 2
(1 row)
The results above tell us:
- The
ridestable is split across 7 ranges, with six leaseholders on node 2 and one leaseholder on node 1. - The
userstable is just a single range with its leaseholder on node 2.
Now, given the WHERE condition of the join, the full table scan of rides, across all of its 7 ranges, is particularly wasteful. To speed up the query, you can create a secondary index on the WHERE condition (rides.start_time) storing the join key (rides.rider_id):
$ cockroach sql \
--insecure \
--host=<address of any node> \
--database=movr \
--execute="CREATE INDEX ON rides (start_time) STORING (rider_id);"
The rides table contains 1 million rows, so adding this index will take a few minutes.
Adding the secondary index reduced the query time from 1573ms to 61.56ms:
$ ./tuning.py \
--host=<address of any node> \
--statement="SELECT count(DISTINCT users.id) \
FROM users \
INNER JOIN rides ON rides.rider_id = users.id \
WHERE start_time BETWEEN '2018-07-20 00:00:00' AND '2018-07-21 00:00:00'" \
--repeat=50 \
--times
Result:
['count']
['1998']
Times (milliseconds):
[66.78199768066406, 63.83800506591797, 65.57297706604004, 63.04502487182617, 61.54489517211914, 61.51890754699707, 60.935020446777344, 61.8891716003418, 60.71019172668457, 64.44311141967773, 64.82601165771484, 61.5849494934082, 62.136173248291016, 62.78491020202637, 62.70194053649902, 61.837196350097656, 64.13102149963379, 62.66903877258301, 71.14315032958984, 61.08808517456055, 58.36200714111328, 60.003042221069336, 58.743953704833984, 59.05413627624512, 60.63103675842285, 60.12582778930664, 61.02705001831055, 62.548160552978516, 61.45000457763672, 65.27113914489746, 60.18996238708496, 59.36002731323242, 60.13298034667969, 59.8299503326416, 59.168100357055664, 65.20915031433105, 60.43219566345215, 58.91895294189453, 58.67791175842285, 59.50117111206055, 59.977054595947266, 65.39011001586914, 62.3931884765625, 69.40793991088867, 61.64288520812988, 66.52498245239258, 69.78988647460938, 60.96601486206055, 57.71303176879883, 61.81192398071289]
Median time (milliseconds):
61.5649223328
To understand why performance improved, again use EXPLAIN to see the new query plan:
$ cockroach sql \
--insecure \
--host=<address of any node> \
--database=movr \
--execute="EXPLAIN SELECT count(DISTINCT users.id) \
FROM users \
INNER JOIN rides ON rides.rider_id = users.id \
WHERE start_time BETWEEN '2018-07-20 00:00:00' AND '2018-07-21 00:00:00';"
tree | field | description
+---------------------+-------------+-------------------------------------------------------+
group | |
│ | aggregate 0 | count(DISTINCT id)
│ | scalar |
└── render | |
└── join | |
│ | type | inner
│ | equality | (id) = (rider_id)
├── scan | |
│ | table | users@users_name_idx
│ | spans | ALL
└── scan | |
| table | rides@rides_start_time_idx
| spans | /2018-07-20T00:00:00Z-/2018-07-21T00:00:00.000000001Z
(13 rows)
Notice that CockroachDB now starts by using rides@rides_start_time_idx secondary index to retrieve the relevant rides without needing to scan the full rides table.
Let's check the ranges for the new index:
$ cockroach sql \
--insecure \
--host=<address of any node> \
--database=movr \
--execute="SHOW EXPERIMENTAL_RANGES FROM INDEX rides@rides_start_time_idx;"
start_key | end_key | range_id | replicas | lease_holder
+------------------------------------------------------------------------------------------+------------------------------------------------------------------------------------------+----------+----------+--------------+
NULL | /2018-07-11T01:37:36.138325Z/"new york"/"\xd4\xe3\u007f\xbc2\xc0Mv\x81B\xd6\xc7٘\x9f\xe6" | 45 | {1,2,3} | 2
/2018-07-11T01:37:36.138325Z/"new york"/"\xd4\xe3\u007f\xbc2\xc0Mv\x81B\xd6\xc7٘\x9f\xe6" | NULL | 50 | {1,2,3} | 2
(2 rows)
This tells us that the index is stored in 2 ranges, with the leaseholders for both of them on node 2. Based on the output of SHOW EXPERIMENTAL_RANGES FROM TABLE users that we saw earlier, we already know that the leaseholder for the users table is on node 2.
Using IN (list) with a subquery
Now let's say you want to get the latest ride of each of the 5 most used vehicles. To do this, you might think to use a subquery to get the IDs of the 5 most frequent vehicles from the rides table, passing the results into the IN list of another query to get the most recent ride of each of the 5 vehicles:
$ ./tuning.py \
--host=<address of any node> \
--statement="SELECT vehicle_id, max(end_time) \
FROM rides \
WHERE vehicle_id IN ( \
SELECT vehicle_id \
FROM rides \
GROUP BY vehicle_id \
ORDER BY count(*) DESC \
LIMIT 5 \
) \
GROUP BY vehicle_id" \
--repeat=20 \
--times
Result:
['vehicle_id', 'max']
['3c950d36-c2b8-48d0-87d3-e0d6f570af62', '2018-08-02 03:06:31.293184']
['0962cdca-9d85-457c-9616-cc2ae2d32008', '2018-08-02 03:01:25.414512']
['78fdd6f8-c6a1-42df-a89f-cd65b7bb8be9', '2018-08-02 02:47:43.755989']
['c6541da5-9858-4e3f-9b49-992e206d2c50', '2018-08-02 02:14:50.543760']
['35752c4c-b878-4436-8330-8d7246406a55', '2018-08-02 03:08:49.823209']
Times (milliseconds):
[3012.6540660858154, 2456.5110206604004, 2482.675075531006, 2488.3930683135986, 2474.393129348755, 2494.3790435791016, 2504.063129425049, 2491.326093673706, 2507.4589252471924, 2482.077121734619, 2495.9230422973633, 2497.60103225708, 2478.4271717071533, 2496.574878692627, 2506.395101547241, 2468.4300422668457, 2476.508140563965, 2497.958183288574, 2480.7958602905273, 2484.0168952941895]
Median time (milliseconds):
2489.85958099
However, as you can see, this query is slow because, currently, when the WHERE condition of a query comes from the result of a subquery, CockroachDB scans the entire table, even if there is an available index. Use EXPLAIN to see this in more detail:
$ cockroach sql \
--insecure \
--host=<address of any node> \
--database=movr \
--execute="EXPLAIN SELECT vehicle_id, max(end_time) \
FROM rides \
WHERE vehicle_id IN ( \
SELECT vehicle_id \
FROM rides \
GROUP BY vehicle_id \
ORDER BY count(*) DESC \
LIMIT 5 \
) \
GROUP BY vehicle_id;"
tree | field | description
+-------------------------------+-------------+-----------------------------------------------------+
group | |
│ | aggregate 0 | vehicle_id
│ | aggregate 1 | max(end_time)
│ | group by | @1
└── join | |
│ | type | semi
│ | equality | (vehicle_id) = (vehicle_id)
├── scan | |
│ | table | rides@primary
│ | spans | ALL
└── limit | |
└── sort | |
│ | order | -agg0
└── group | |
│ | aggregate 0 | vehicle_id
│ | aggregate 1 | count_rows()
│ | group by | @1
└── scan | |
| table | rides@rides_auto_index_fk_vehicle_city_ref_vehicles
| spans | ALL
(20 rows)
This is a complex query plan, but the important thing to note is the full table scan of rides@primary above the subquery. This shows you that, after the subquery returns the IDs of the top 5 vehicles, CockroachDB scans the entire primary index to find the rows with max(end_time) for each vehicle_id, although you might expect CockroachDB to more efficiently use the secondary index on vehicle_id (CockroachDB is working to remove this limitation in a future version).
Using IN (list) with explicit values
Because CockroachDB will not use an available secondary index when using IN (list) with a subquery, it's much more performant to have your application first select the top 5 vehicles:
$ ./tuning.py \
--host=<address of any node> \
--statement="SELECT vehicle_id \
FROM rides \
GROUP BY vehicle_id \
ORDER BY count(*) DESC \
LIMIT 5" \
--repeat=20 \
--times
Result:
['vehicle_id']
['35752c4c-b878-4436-8330-8d7246406a55']
['0962cdca-9d85-457c-9616-cc2ae2d32008']
['c6541da5-9858-4e3f-9b49-992e206d2c50']
['78fdd6f8-c6a1-42df-a89f-cd65b7bb8be9']
['3c950d36-c2b8-48d0-87d3-e0d6f570af62']
Times (milliseconds):
[1049.2329597473145, 1038.0151271820068, 1037.7991199493408, 1036.5591049194336, 1037.7249717712402, 1040.544033050537, 1022.7780342102051, 1056.9651126861572, 1054.3549060821533, 1042.3550605773926, 1042.68217086792, 1031.7370891571045, 1051.880121231079, 1035.8471870422363, 1035.2818965911865, 1035.607099533081, 1040.0230884552002, 1048.8879680633545, 1056.014060974121, 1036.1089706420898]
Median time (milliseconds):
1039.01910782
And then put the results into the IN list to get the most recent rides of the vehicles:
$ ./tuning.py \
--host=<address of any node> \
--statement="SELECT vehicle_id, max(end_time) \
FROM rides \
WHERE vehicle_id IN ( \
'35752c4c-b878-4436-8330-8d7246406a55', \
'0962cdca-9d85-457c-9616-cc2ae2d32008', \
'c6541da5-9858-4e3f-9b49-992e206d2c50', \
'78fdd6f8-c6a1-42df-a89f-cd65b7bb8be9', \
'3c950d36-c2b8-48d0-87d3-e0d6f570af62' \
) \
GROUP BY vehicle_id;" \
--repeat=20 \
--times
Result:
['vehicle_id', 'max']
['35752c4c-b878-4436-8330-8d7246406a55', '2018-08-02 03:08:49.823209']
['0962cdca-9d85-457c-9616-cc2ae2d32008', '2018-08-02 03:01:25.414512']
['3c950d36-c2b8-48d0-87d3-e0d6f570af62', '2018-08-02 03:06:31.293184']
['78fdd6f8-c6a1-42df-a89f-cd65b7bb8be9', '2018-08-02 02:47:43.755989']
['c6541da5-9858-4e3f-9b49-992e206d2c50', '2018-08-02 02:14:50.543760']
Times (milliseconds):
[1165.5981540679932, 1135.9851360321045, 1201.0550498962402, 1135.0820064544678, 1195.7061290740967, 1132.0109367370605, 1134.9878311157227, 1175.88210105896, 1174.0548610687256, 1152.566909790039, 1164.9351119995117, 1175.5108833312988, 1161.651849746704, 1195.3318119049072, 1162.4629497528076, 1156.1191082000732, 1127.0110607147217, 1165.4651165008545, 1159.6789360046387, 1190.3491020202637]
Median time (milliseconds):
1163.69903088
This approach reduced the query time from 2489.85ms (query with subquery) to 2202.70ms (2 distinct queries).
Step 7. Test/tune write performance
- Bulk inserting into an existing table
- Minimizing unused indexes
- Retrieving the ID of a newly inserted row
Bulk inserting into an existing table
Moving on to writes, let's imagine that you have a batch of 100 new users to insert into the users table. The most obvious approach is to insert each row using 100 separate INSERT statements:
For the purpose of demonstration, the command below inserts the same user 100 times, each time with a different unique ID. Note also that you're now adding the --cumulative flag to print the total time across all 100 inserts.
$ ./tuning.py \
--host=<address of any node> \
--statement="INSERT INTO users VALUES (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347')" \
--repeat=100 \
--times \
--cumulative
Times (milliseconds):
[10.773181915283203, 12.186050415039062, 9.711980819702148, 9.730815887451172, 10.200977325439453, 9.32002067565918, 9.002923965454102, 9.426116943359375, 9.312152862548828, 8.329153060913086, 9.626150131225586, 8.965015411376953, 9.562969207763672, 9.305000305175781, 9.34910774230957, 7.394075393676758, 9.3231201171875, 9.066104888916016, 8.419036865234375, 9.158134460449219, 9.278059005737305, 8.022069931030273, 8.542060852050781, 9.237051010131836, 8.165121078491211, 8.094072341918945, 8.025884628295898, 8.04591178894043, 9.728193283081055, 8.485078811645508, 7.967948913574219, 9.319067001342773, 8.099079132080078, 9.041070938110352, 10.046005249023438, 10.684013366699219, 9.672880172729492, 8.129119873046875, 8.10098648071289, 7.884979248046875, 9.484052658081055, 8.594036102294922, 9.479045867919922, 9.239912033081055, 9.16600227355957, 9.155988693237305, 9.392976760864258, 11.08694076538086, 9.402990341186523, 8.034944534301758, 8.053064346313477, 8.03995132446289, 8.891820907592773, 8.054971694946289, 8.903980255126953, 9.057998657226562, 9.713888168334961, 7.99107551574707, 8.114814758300781, 8.677959442138672, 11.178970336914062, 9.272098541259766, 9.281158447265625, 8.177995681762695, 9.47880744934082, 10.025978088378906, 8.352041244506836, 8.320808410644531, 10.892868041992188, 8.227825164794922, 8.220911026000977, 9.625911712646484, 10.272026062011719, 8.116960525512695, 10.786771774291992, 9.073972702026367, 9.686946868896484, 9.903192520141602, 9.887933731079102, 9.399890899658203, 9.413003921508789, 8.594036102294922, 8.433103561401367, 9.271860122680664, 8.529901504516602, 9.474992752075195, 9.005069732666016, 9.341001510620117, 9.388923645019531, 9.775876998901367, 8.558988571166992, 9.613990783691406, 8.897066116333008, 8.642911911010742, 9.527206420898438, 8.274078369140625, 9.073972702026367, 9.637832641601562, 8.516788482666016, 9.564876556396484]
Median time (milliseconds):
9.20152664185
Cumulative time (milliseconds):
910.985708237
The 100 inserts took 910.98ms to complete, which isn't bad. However, it's significantly faster to use a single INSERT statement with 100 comma-separated VALUES clauses:
$ ./tuning.py \
--host=<address of any node> \
--statement="INSERT INTO users VALUES \
(gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), \
(gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), \
(gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), \
(gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), \
(gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), \
(gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), \
(gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), \
(gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), \
(gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), \
(gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347'), (gen_random_uuid(), 'new york', 'Max Roach', '411 Drum Street', '173635282937347')" \
--repeat=1 \
--cumulative
Median time (milliseconds):
15.4001712799
Cumulative time (milliseconds):
15.4001712799
As you can see, this multi-row INSERT technique reduced the total time for 100 inserts from 910.98ms to 15.40ms. It's useful to note that this technique is equally effective for UPSERT and DELETE statements as well.
Minimizing unused indexes
Earlier, we saw how important secondary indexes are for read performance. For writes, however, it's important to recognized the overhead that they create.
Let's consider the users table:
$ cockroach sql \
--insecure \
--host=<address of any node> \
--database=movr \
--execute="SHOW INDEXES FROM users;"
table_name | index_name | non_unique | seq_in_index | column_name | direction | storing | implicit
+------------+----------------+------------+--------------+-------------+-----------+---------+----------+
users | primary | false | 1 | city | ASC | false | false
users | primary | false | 2 | id | ASC | false | false
users | users_name_idx | true | 1 | name | ASC | false | false
users | users_name_idx | true | 2 | credit_card | N/A | true | false
users | users_name_idx | true | 3 | city | ASC | false | true
users | users_name_idx | true | 4 | id | ASC | false | true
(6 rows)
This table has the primary index (the full table) and a secondary index on name that is also storing credit_card. This means that whenever a row is inserted, or whenever name, credit_card, city, or id are modified in existing rows, both indexes are updated.
To make this more concrete, let's count how many rows have a name that starts with C and then update those rows to all have the same name:
$ ./tuning.py \
--host=<address of any node> \
--statement="SELECT count(*) \
FROM users \
WHERE name LIKE 'C%'" \
--repeat=1
['count']
['179']
Median time (milliseconds):
2.52604484558
$ ./tuning.py \
--host=<address of any node> \
--statement="UPDATE users \
SET name = 'Carl Kimball' \
WHERE name LIKE 'C%'" \
--repeat=1
Median time (milliseconds):
52.2060394287
Because name is in both the primary and users_name_idx indexes, for each of the 168 rows, 2 keys were updated.
Now, assuming that the users_name_idx index is no longer needed, lets drop the index and execute an equivalent query:
$ cockroach sql \
--insecure \
--host=<address of any node> \
--database=movr \
--execute="DROP INDEX users_name_idx;"
$ ./tuning.py \
--host=<address of any node> \
--statement="UPDATE users \
SET name = 'Peedie Hirata' \
WHERE name = 'Carl Kimball'" \
--repeat=1
Median time (milliseconds):
22.7289199829
Before, when both the primary and secondary indexes needed to be updated, the updates took 52.20ms. Now, after dropping the secondary index, an equivalent update took only 22.72ms.
Retrieving the ID of a newly inserted row
Now let's focus on the common case of inserting a row into a table and then retrieving the ID of the new row to do some follow-up work. One approach is to execute two statements, an INSERT to insert the row and then a SELECT to get the new ID:
$ ./tuning.py \
--host=<address of any node> \
--statement="INSERT INTO users VALUES (gen_random_uuid(), 'new york', 'Toni Brooks', '800 Camden Lane, Brooklyn, NY 11218', '98244843845134960')" \
--repeat=1
Median time (milliseconds):
10.4398727417
$ ./tuning.py \
--host=<address of any node> \
--statement="SELECT id FROM users WHERE name = 'Toni Brooks'" \
--repeat=1
Result:
['id']
['ae563e17-ad59-4307-a99e-191e682b4278']
Median time (milliseconds):
5.53798675537
Combined, these statements are relatively fast, at 15.96ms, but an even more performant approach is to append RETURNING id to the end of the INSERT:
$ ./tuning.py \
--host=<address of any node> \
--statement="INSERT INTO users VALUES (gen_random_uuid(), 'new york', 'Brian Brooks', '800 Camden Lane, Brooklyn, NY 11218', '98244843845134960') \
RETURNING id" \
--repeat=1
Result:
['id']
['3d16500e-cb2e-462e-9c83-db0965d6deaf']
Median time (milliseconds):
9.48596000671
At just 9.48ms, this approach is faster due to the write and read executing in one instead of two client-server roundtrips. Note also that, as discussed earlier, if the leaseholder for the table happens to be on a different node than the query is running against, that introduces additional network hops and latency.
Multi-region deployment
Given that Movr is active on both US coasts, you'll now scale the cluster into two new regions, us-west1-a and us-west2-a, each with 3 nodes and an extra instance for simulating regional client traffic.
Step 8. Create more instances
Create 6 more instances, 3 in the
us-west1-azone (Oregon), and 3 in theus-west2-azone (Los Angeles). While creating each instance:- Use the
n1-standard-4machine type (4 vCPUs, 15 GB memory). - Use the Ubuntu 16.04 OS image.
- Create and mount a local SSD.
- To apply the Web UI firewall rule you created earlier, click Management, disk, networking, SSH keys, select the Networking tab, and then enter
cockroachdbin the Network tags field.
- Use the
Note the internal IP address of each
n1-standard-4instance. You'll need these addresses when starting the CockroachDB nodes.Create an additional instance in the
us-west1-aandus-west2-azones. These can be smaller, such asn1-standard-1.
Step 9. Scale the cluster
SSH to one of the
n1-standard-4instances in theus-west1-azone.Download the CockroachDB archive for Linux, extract the binary, and copy it into the
PATH:$ curl https://binaries.cockroachdb.com/cockroach-v2.1.11.linux-amd64.tgz \ | tar -xz$ sudo cp -i cockroach-v2.1.11.linux-amd64/cockroach /usr/local/bin/Run the
cockroach startcommand:$ cockroach start \ --insecure \ --advertise-host=<node internal address> \ --join=<same as earlier> \ --locality=cloud=gce,region=us-west1,zone=us-west1-a \ --cache=.25 \ --max-sql-memory=.25 \ --backgroundRepeat steps 1 - 3 for the other two
n1-standard-4instances in theus-west1-azone.SSH to one of the
n1-standard-4instances in theus-west2-azone.Download the CockroachDB archive for Linux, extract the binary, and copy it into the
PATH:$ curl https://binaries.cockroachdb.com/cockroach-v2.1.11.linux-amd64.tgz \ | tar -xz$ sudo cp -i cockroach-v2.1.11.linux-amd64/cockroach /usr/local/bin/Run the
cockroach startcommand:$ cockroach start \ --insecure \ --advertise-host=<node1 internal address> \ --join=<same as earlier> \ --locality=cloud=gce,region=us-west2,zone=us-west2-a \ --cache=.25 \ --max-sql-memory=.25 \ --backgroundRepeat steps 5 - 7 for the other two
n1-standard-4instances in theus-west2-azone.
Step 10. Install the Python client
In each of the new zones, SSH to the instance not running a CockroachDB node, and install the Python client as described in step 5 above.
Step 11. Check rebalancing
Since you started each node with the --locality flag set to its GCE zone, over the next minutes, CockroachDB will rebalance data evenly across the zones.
To check this, access the Web UI on any node at <node address>:8080 and look at the Node List. You'll see that the range count is more or less even across all nodes:
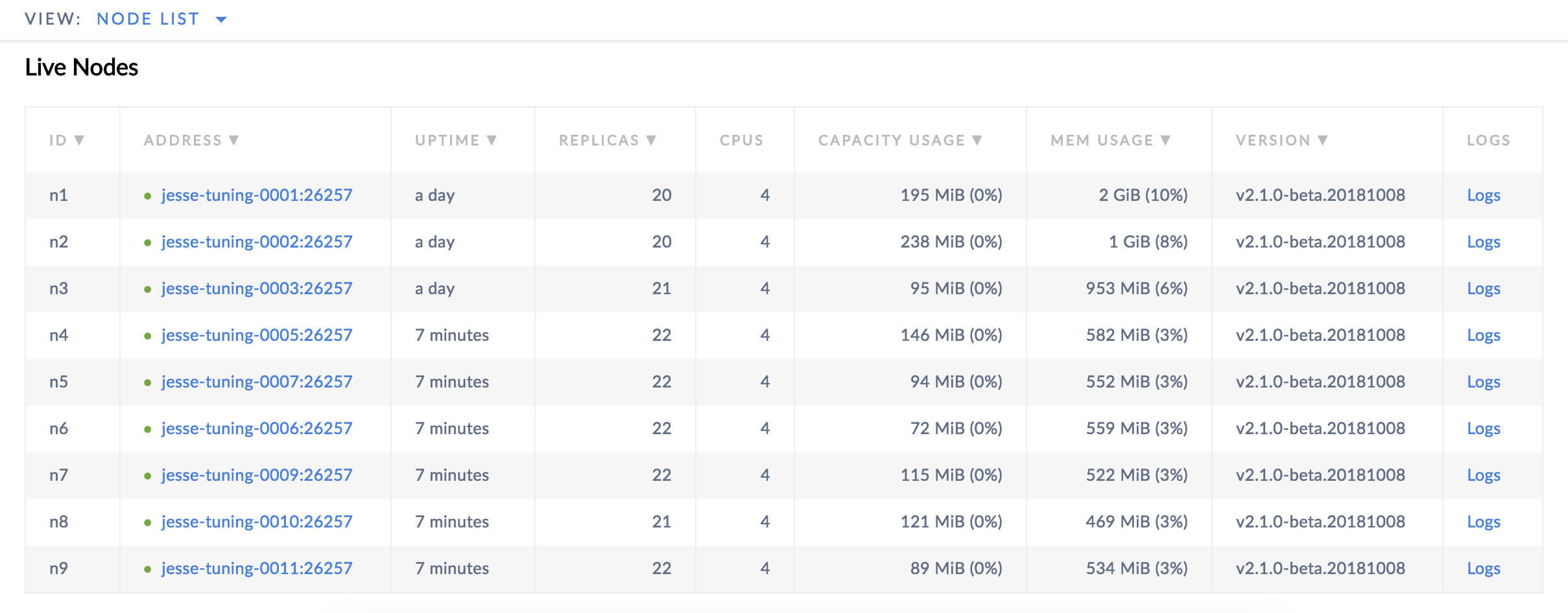
For reference, here's how the nodes map to zones:
| Node IDs | Zone |
|---|---|
| 1-3 | us-east1-b (South Carolina) |
| 4-6 | us-west1-a (Oregon) |
| 7-9 | us-west2-a (Los Angeles) |
To verify even balancing at range level, SSH to one of the instances not running CockroachDB and run the SHOW EXPERIMENTAL_RANGES statement:
$ cockroach sql \
--insecure \
--host=<address of any node> \
--database=movr \
--execute="SHOW EXPERIMENTAL_RANGES FROM TABLE vehicles;"
start_key | end_key | range_id | replicas | lease_holder
+-----------+---------+----------+----------+--------------+
NULL | NULL | 33 | {3,4,7} | 7
(1 row)
In this case, we can see that, for the single range containing vehicles data, one replica is in each zone, and the leaseholder is in the us-west2-a zone.
Step 12. Test performance
In general, all of the tuning techniques featured in the single-region scenario above still apply in a multi-region deployment. However, the fact that data and leaseholders are spread across the US means greater latencies in many cases.
Reads
For example, imagine we are a Movr administrator in New York, and we want to get the IDs and descriptions of all New York-based bikes that are currently in use:
SSH to the instance in
us-east1-bwith the Python client.Query for the data:
$ ./tuning.py \ --host=<address of a node in us-east1-b> \ --statement="SELECT id, ext FROM vehicles \ WHERE city = 'new york' \ AND type = 'bike' \ AND status = 'in_use'" \ --repeat=50 \ --timesResult: ['id', 'ext'] ['0068ee24-2dfb-437d-9a5d-22bb742d519e', "{u'color': u'green', u'brand': u'Kona'}"] ['01b80764-283b-4232-8961-a8d6a4121a08', "{u'color': u'green', u'brand': u'Pinarello'}"] ['02a39628-a911-4450-b8c0-237865546f7f', "{u'color': u'black', u'brand': u'Schwinn'}"] ['02eb2a12-f465-4575-85f8-a4b77be14c54', "{u'color': u'black', u'brand': u'Pinarello'}"] ['02f2fcc3-fea6-4849-a3a0-dc60480fa6c2', "{u'color': u'red', u'brand': u'FujiCervelo'}"] ['034d42cf-741f-428c-bbbb-e31820c68588', "{u'color': u'yellow', u'brand': u'Santa Cruz'}"] ... Times (milliseconds): [933.8209629058838, 72.02410697937012, 72.45206832885742, 72.39294052124023, 72.8158950805664, 72.07584381103516, 72.21412658691406, 71.96712493896484, 71.75517082214355, 72.16811180114746, 71.78592681884766, 72.91603088378906, 71.91109657287598, 71.4719295501709, 72.40676879882812, 71.8080997467041, 71.84004783630371, 71.98500633239746, 72.40891456604004, 73.75001907348633, 71.45905494689941, 71.53081893920898, 71.46596908569336, 72.07608222961426, 71.94995880126953, 71.41804695129395, 71.29096984863281, 72.11899757385254, 71.63381576538086, 71.3050365447998, 71.83194160461426, 71.20394706726074, 70.9981918334961, 72.79205322265625, 72.63493537902832, 72.15285301208496, 71.8698501586914, 72.30591773986816, 71.53582572937012, 72.69001007080078, 72.03006744384766, 72.56317138671875, 71.61688804626465, 72.17121124267578, 70.20092010498047, 72.12018966674805, 73.34589958190918, 73.01592826843262, 71.49410247802734, 72.19099998474121] Median time (milliseconds): 72.0270872116
As we saw earlier, the leaseholder for the vehicles table is in us-west2-a (Los Angeles), so our query had to go from the gateway node in us-east1-b all the way to the west coast and then back again before returning data to the client.
For contrast, imagine we are now a Movr administrator in Los Angeles, and we want to get the IDs and descriptions of all Los Angeles-based bikes that are currently in use:
SSH to the instance in
us-west2-awith the Python client.Query for the data:
$ ./tuning.py \ --host=<address of a node in us-west2-a> \ --statement="SELECT id, ext FROM vehicles \ WHERE city = 'los angeles' \ AND type = 'bike' \ AND status = 'in_use'" \ --repeat=50 \ --timesResult: ['id', 'ext'] ['00078349-94d4-43e6-92be-8b0d1ac7ee9f', "{u'color': u'blue', u'brand': u'Merida'}"] ['003f84c4-fa14-47b2-92d4-35a3dddd2d75', "{u'color': u'red', u'brand': u'Kona'}"] ['0107a133-7762-4392-b1d9-496eb30ee5f9', "{u'color': u'yellow', u'brand': u'Kona'}"] ['0144498b-4c4f-4036-8465-93a6bea502a3', "{u'color': u'blue', u'brand': u'Pinarello'}"] ['01476004-fb10-4201-9e56-aadeb427f98a', "{u'color': u'black', u'brand': u'Merida'}"] Times (milliseconds): [782.6759815216064, 8.564949035644531, 8.226156234741211, 7.949113845825195, 7.86590576171875, 7.842063903808594, 7.674932479858398, 7.555961608886719, 7.642984390258789, 8.024930953979492, 7.717132568359375, 8.46409797668457, 7.520914077758789, 7.6541900634765625, 7.458925247192383, 7.671833038330078, 7.740020751953125, 7.771015167236328, 7.598161697387695, 8.411169052124023, 7.408857345581055, 7.469892501831055, 7.524967193603516, 7.764101028442383, 7.750988006591797, 7.2460174560546875, 6.927967071533203, 7.822990417480469, 7.27391242980957, 7.730960845947266, 7.4710845947265625, 7.4310302734375, 7.33494758605957, 7.455110549926758, 7.021188735961914, 7.083892822265625, 7.812976837158203, 7.625102996826172, 7.447957992553711, 7.179021835327148, 7.504940032958984, 7.224082946777344, 7.257938385009766, 7.714986801147461, 7.4939727783203125, 7.6160430908203125, 7.578849792480469, 7.890939712524414, 7.546901702880859, 7.411956787109375] Median time (milliseconds): 7.6071023941
Because the leaseholder for vehicles is in the same zone as the client request, this query took just 7.60ms compared to the similar query in New York that took 72.02ms.
Writes
The geographic distribution of data impacts write performance as well. For example, imagine 100 people in Seattle and 100 people in New York want to create new Movr accounts:
SSH to the instance in
us-west1-awith the Python client.Create 100 Seattle-based users:
./tuning.py \ --host=<address of a node in us-west1-a> \ --statement="INSERT INTO users VALUES (gen_random_uuid(), 'seattle', 'Seatller', '111 East Street', '1736352379937347')" \ --repeat=100 \ --timesTimes (milliseconds): [277.4538993835449, 50.12702941894531, 47.75214195251465, 48.13408851623535, 47.872066497802734, 48.65407943725586, 47.78695106506348, 49.14689064025879, 52.770137786865234, 49.00097846984863, 48.68602752685547, 47.387123107910156, 47.36208915710449, 47.6841926574707, 46.49209976196289, 47.06096649169922, 46.753883361816406, 46.304941177368164, 48.90894889831543, 48.63715171813965, 48.37393760681152, 49.23295974731445, 50.13418197631836, 48.310041427612305, 48.57516288757324, 47.62911796569824, 47.77693748474121, 47.505855560302734, 47.89996147155762, 49.79205131530762, 50.76479911804199, 50.21500587463379, 48.73299598693848, 47.55592346191406, 47.35088348388672, 46.7071533203125, 43.00808906555176, 43.1060791015625, 46.02813720703125, 47.91092872619629, 68.71294975280762, 49.241065979003906, 48.9039421081543, 47.82295227050781, 48.26998710632324, 47.631025314331055, 64.51892852783203, 48.12812805175781, 67.33417510986328, 48.603057861328125, 50.31013488769531, 51.02396011352539, 51.45716667175293, 50.85396766662598, 49.07512664794922, 47.49894142150879, 44.67201232910156, 43.827056884765625, 44.412851333618164, 46.69189453125, 49.55601692199707, 49.16882514953613, 49.88598823547363, 49.31306838989258, 46.875, 46.69594764709473, 48.31886291503906, 48.378944396972656, 49.0570068359375, 49.417972564697266, 48.22111129760742, 50.662994384765625, 50.58097839355469, 75.44088363647461, 51.05400085449219, 50.85110664367676, 48.187971115112305, 56.7781925201416, 42.47403144836426, 46.2191104888916, 53.96890640258789, 46.697139739990234, 48.99096488952637, 49.1330623626709, 46.34690284729004, 47.09315299987793, 46.39410972595215, 46.51689529418945, 47.58000373840332, 47.924041748046875, 48.426151275634766, 50.22597312927246, 50.1859188079834, 50.37498474121094, 49.861907958984375, 51.477909088134766, 73.09293746948242, 48.779964447021484, 45.13692855834961, 42.2968864440918] Median time (milliseconds): 48.4025478363SSH to the instance in
us-east1-bwith the Python client.Create 100 new NY-based users:
./tuning.py \ --host=<address of a node in us-east1-b> \ --statement="INSERT INTO users VALUES (gen_random_uuid(), 'new york', 'New Yorker', '111 West Street', '9822222379937347')" \ --repeat=100 \ --timesTimes (milliseconds): [131.05082511901855, 116.88899993896484, 115.15498161315918, 117.095947265625, 121.04082107543945, 115.8750057220459, 113.80696296691895, 113.05880546569824, 118.41201782226562, 125.30899047851562, 117.5389289855957, 115.23890495300293, 116.84799194335938, 120.0411319732666, 115.62800407409668, 115.08989334106445, 113.37089538574219, 115.15498161315918, 115.96989631652832, 133.1961154937744, 114.25995826721191, 118.09396743774414, 122.24102020263672, 116.14608764648438, 114.80998992919922, 131.9139003753662, 114.54391479492188, 115.15307426452637, 116.7759895324707, 135.10799407958984, 117.18511581420898, 120.15485763549805, 118.0570125579834, 114.52388763427734, 115.28396606445312, 130.00011444091797, 126.45292282104492, 142.69423484802246, 117.60401725769043, 134.08493995666504, 117.47002601623535, 115.75007438659668, 117.98381805419922, 115.83089828491211, 114.88890647888184, 113.23404312133789, 121.1700439453125, 117.84791946411133, 115.35286903381348, 115.0820255279541, 116.99700355529785, 116.67394638061523, 116.1041259765625, 114.67289924621582, 112.98894882202148, 117.1119213104248, 119.78602409362793, 114.57300186157227, 129.58717346191406, 118.37983131408691, 126.68204307556152, 118.30306053161621, 113.27195167541504, 114.22920227050781, 115.80777168273926, 116.81294441223145, 114.76683616638184, 115.1430606842041, 117.29192733764648, 118.24417114257812, 116.56999588012695, 113.8620376586914, 114.88819122314453, 120.80597877502441, 132.39002227783203, 131.00910186767578, 114.56179618835449, 117.03896522521973, 117.72680282592773, 115.6010627746582, 115.27681350708008, 114.52317237854004, 114.87483978271484, 117.78903007507324, 116.65701866149902, 122.6949691772461, 117.65193939208984, 120.5449104309082, 115.61179161071777, 117.54202842712402, 114.70890045166016, 113.58809471130371, 129.7171115875244, 117.57993698120117, 117.1119213104248, 117.64001846313477, 140.66505432128906, 136.41691207885742, 116.24789237976074, 115.19908905029297] Median time (milliseconds): 116.868495941
It took 48.40ms to create a user in Seattle and 116.86ms to create a user in New York. To better understand this discrepancy, let's look at the distribution of data for the users table:
$ cockroach sql \
--insecure \
--host=<address of any node> \
--database=movr \
--execute="SHOW EXPERIMENTAL_RANGES FROM TABLE users;"
start_key | end_key | range_id | replicas | lease_holder
+-----------+---------+----------+----------+--------------+
NULL | NULL | 49 | {2,6,8} | 6
(1 row)
For the single range containing users data, one replica is in each zone, with the leaseholder in the us-west1-a zone. This means that:
- When creating a user in Seattle, the request doesn't have to leave the zone to reach the leaseholder. However, since a write requires consensus from its replica group, the write has to wait for confirmation from either the replica in
us-west1-b(Los Angeles) orus-east1-b(New York) before committing and then returning confirmation to the client. - When creating a user in New York, there are more network hops and, thus, increased latency. The request first needs to travel across the continent to the leaseholder in
us-west1-a. It then has to wait for confirmation from either the replica inus-west1-b(Los Angeles) orus-east1-b(New York) before committing and then returning confirmation to the client back in the east.
Step 13. Partition data by city
For this service, the most effective technique for improving read and write latency is to geo-partition the data by city. In essence, this means changing the way data is mapped to ranges. Instead of an entire table and its indexes mapping to a specific range or set of ranges, all rows in the table and its indexes with a given city will map to a range or set of ranges. Once ranges are defined in this way, we can then use the replication zone feature to pin partitions to specific locations, ensuring that read and write requests from users in a specific city do not have to leave that region.
Partitioning is an enterprise feature, so start off by registering for a 30-day trial license.
Once you've received the trial license, SSH to any node in your cluster and apply the license:
$ cockroach sql \ --insecure \ --host=<address of any node> \ --execute="SET CLUSTER SETTING cluster.organization = '<your org name>';"$ cockroach sql \ --insecure \ --host=<address of any node> \ --execute="SET CLUSTER SETTING enterprise.license = '<your license>';"Define partitions for all tables and their secondary indexes.
Start with the
userstable:$ cockroach sql \ --insecure \ --database=movr \ --host=<address of any node> \ --execute="ALTER TABLE users \ PARTITION BY LIST (city) ( \ PARTITION new_york VALUES IN ('new york'), \ PARTITION boston VALUES IN ('boston'), \ PARTITION washington_dc VALUES IN ('washington dc'), \ PARTITION seattle VALUES IN ('seattle'), \ PARTITION san_francisco VALUES IN ('san francisco'), \ PARTITION los_angeles VALUES IN ('los angeles') \ );"Now define partitions for the
vehiclestable and its secondary indexes:$ cockroach sql \ --insecure \ --database=movr \ --host=<address of any node> \ --execute="ALTER TABLE vehicles \ PARTITION BY LIST (city) ( \ PARTITION new_york VALUES IN ('new york'), \ PARTITION boston VALUES IN ('boston'), \ PARTITION washington_dc VALUES IN ('washington dc'), \ PARTITION seattle VALUES IN ('seattle'), \ PARTITION san_francisco VALUES IN ('san francisco'), \ PARTITION los_angeles VALUES IN ('los angeles') \ );"$ cockroach sql \ --insecure \ --database=movr \ --host=<address of any node> \ --execute="ALTER INDEX vehicles_auto_index_fk_city_ref_users \ PARTITION BY LIST (city) ( \ PARTITION new_york_idx VALUES IN ('new york'), \ PARTITION boston_idx VALUES IN ('boston'), \ PARTITION washington_dc_idx VALUES IN ('washington dc'), \ PARTITION seattle_idx VALUES IN ('seattle'), \ PARTITION san_francisco_idx VALUES IN ('san francisco'), \ PARTITION los_angeles_idx VALUES IN ('los angeles') \ );"Next, define partitions for the
ridestable and its secondary indexes:$ cockroach sql \ --insecure \ --database=movr \ --host=<address of any node> \ --execute="ALTER TABLE rides \ PARTITION BY LIST (city) ( \ PARTITION new_york VALUES IN ('new york'), \ PARTITION boston VALUES IN ('boston'), \ PARTITION washington_dc VALUES IN ('washington dc'), \ PARTITION seattle VALUES IN ('seattle'), \ PARTITION san_francisco VALUES IN ('san francisco'), \ PARTITION los_angeles VALUES IN ('los angeles') \ );"$ cockroach sql \ --insecure \ --database=movr \ --host=<address of any node> \ --execute="ALTER INDEX rides_auto_index_fk_city_ref_users \ PARTITION BY LIST (city) ( \ PARTITION new_york_idx1 VALUES IN ('new york'), \ PARTITION boston_idx1 VALUES IN ('boston'), \ PARTITION washington_dc_idx1 VALUES IN ('washington dc'), \ PARTITION seattle_idx1 VALUES IN ('seattle'), \ PARTITION san_francisco_idx1 VALUES IN ('san francisco'), \ PARTITION los_angeles_idx1 VALUES IN ('los angeles') \ );"$ cockroach sql \ --insecure \ --database=movr \ --host=<address of any node> \ --execute="ALTER INDEX rides_auto_index_fk_vehicle_city_ref_vehicles \ PARTITION BY LIST (vehicle_city) ( \ PARTITION new_york_idx2 VALUES IN ('new york'), \ PARTITION boston_idx2 VALUES IN ('boston'), \ PARTITION washington_dc_idx2 VALUES IN ('washington dc'), \ PARTITION seattle_idx2 VALUES IN ('seattle'), \ PARTITION san_francisco_idx2 VALUES IN ('san francisco'), \ PARTITION los_angeles_idx2 VALUES IN ('los angeles') \ );"Finally, drop an unused index on
ridesrather than partition it:$ cockroach sql \ --insecure \ --database=movr \ --host=<address of any node> \ --execute="DROP INDEX rides_start_time_idx;"Note:The
ridestable contains 1 million rows, so dropping this index will take a few minutes.Now create replication zones to require city data to be stored on specific nodes based on node locality.
City Locality New York zone=us-east1-bBoston zone=us-east1-bWashington DC zone=us-east1-bSeattle zone=us-west1-aSan Francisco zone=us-west2-aLos Angeles zone=us-west2-aNote:Since our nodes are located in 3 specific GCE zones, we're only going to use the
zone=portion of node locality. If we were using multiple zones per regions, we would likely use theregion=portion of the node locality instead.Start with the
userstable partitions:$ cockroach sql --execute="ALTER PARTITION new_york OF TABLE movr.users CONFIGURE ZONE USING constraints='[+zone=us-east1-b]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION boston OF TABLE movr.users CONFIGURE ZONE USING constraints='[+zone=us-east1-b]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION washington_dc OF TABLE movr.users CONFIGURE ZONE USING constraints='[+zone=us-east1-b]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION seattle OF TABLE movr.users CONFIGURE ZONE USING constraints='[+zone=us-west1-a]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION san_francisco OF TABLE movr.users CONFIGURE ZONE USING constraints='[+zone=us-west2-a]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION los_angeles OF TABLE movr.users CONFIGURE ZONE USING constraints='[+zone=us-west2-a]';" \ --insecure \ --host=<address of any node>Move on to the
vehiclestable and secondary index partitions:$ cockroach sql --execute="ALTER PARTITION new_york OF TABLE movr.vehicles CONFIGURE ZONE USING constraints='[+zone=us-east1-b]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION new_york_idx OF TABLE movr.vehicles CONFIGURE ZONE USING constraints='[+zone=us-east1-b]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION boston OF TABLE movr.vehicles CONFIGURE ZONE USING constraints='[+zone=us-east1-b]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION boston_idx OF TABLE movr.vehicles CONFIGURE ZONE USING constraints='[+zone=us-east1-b]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION washington_dc OF TABLE movr.vehicles CONFIGURE ZONE USING constraints='[+zone=us-east1-b]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION washington_dc_idx OF TABLE movr.vehicles CONFIGURE ZONE USING constraints='[+zone=us-east1-b]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION seattle OF TABLE movr.vehicles CONFIGURE ZONE USING constraints='[+zone=us-west1-a]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION seattle_idx OF TABLE movr.vehicles CONFIGURE ZONE USING constraints='[+zone=us-west1-a]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION san_francisco OF TABLE movr.vehicles CONFIGURE ZONE USING constraints='[+zone=us-west2-a]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION san_francisco_idx OF TABLE movr.vehicles CONFIGURE ZONE USING constraints='[+zone=us-west2-a]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION los_angeles OF TABLE movr.vehicles CONFIGURE ZONE USING constraints='[+zone=us-west2-a]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION los_angeles_idx OF TABLE movr.vehicles CONFIGURE ZONE USING constraints='[+zone=us-west2-a]';" \ --insecure \ --host=<address of any node>Finish with the
ridestable and secondary index partitions:$ cockroach sql --execute="ALTER PARTITION new_york OF TABLE movr.rides CONFIGURE ZONE USING constraints='[+zone=us-east1-b]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION new_york_idx1 OF TABLE movr.rides CONFIGURE ZONE USING constraints='[+zone=us-east1-b]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION new_york_idx2 OF TABLE movr.rides CONFIGURE ZONE USING constraints='[+zone=us-east1-b]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION boston OF TABLE movr.rides CONFIGURE ZONE USING constraints='[+zone=us-east1-b]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION boston_idx1 OF TABLE movr.rides CONFIGURE ZONE USING constraints='[+zone=us-east1-b]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION boston_idx2 OF TABLE movr.rides CONFIGURE ZONE USING constraints='[+zone=us-east1-b]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION washington_dc OF TABLE movr.rides CONFIGURE ZONE USING constraints='[+zone=us-east1-b]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION washington_dc_idx OF TABLE movr.rides CONFIGURE ZONE USING constraints='[+zone=us-east1-b]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION washington_dc_idx2 OF TABLE movr.rides CONFIGURE ZONE USING constraints='[+zone=us-east1-b]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION seattle OF TABLE movr.rides CONFIGURE ZONE USING constraints='[+zone=us-west1-a]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION seattle_idx1 OF TABLE movr.rides CONFIGURE ZONE USING constraints='[+zone=us-west1-a]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION seattle_idx2 OF TABLE movr.rides CONFIGURE ZONE USING constraints='[+zone=us-west1-a]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION san_francisco OF TABLE movr.rides CONFIGURE ZONE USING constraints='[+zone=us-west2-a]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION san_francisco_idx1 OF TABLE movr.rides CONFIGURE ZONE USING constraints='[+zone=us-west2-a]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION san_francisco_idx2 OF TABLE movr.rides CONFIGURE ZONE USING constraints='[+zone=us-west2-a]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION los_angeles OF TABLE movr.rides CONFIGURE ZONE USING constraints='[+zone=us-west2-a]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION los_angeles_idx1 OF TABLE movr.rides CONFIGURE ZONE USING constraints='[+zone=us-west2-a]';" \ --insecure \ --host=<address of any node>$ cockroach sql --execute="ALTER PARTITION los_angeles_idx2 OF TABLE movr.rides CONFIGURE ZONE USING constraints='[+zone=us-west2-a]';" \ --insecure \ --host=<address of any node>
Step 14. Check rebalancing after partitioning
Over the next minutes, CockroachDB will rebalance all partitions based on the constraints you defined.
To check this at a high level, access the Web UI on any node at <node address>:8080 and look at the Node List. You'll see that the range count is still close to even across all nodes but much higher than before partitioning:
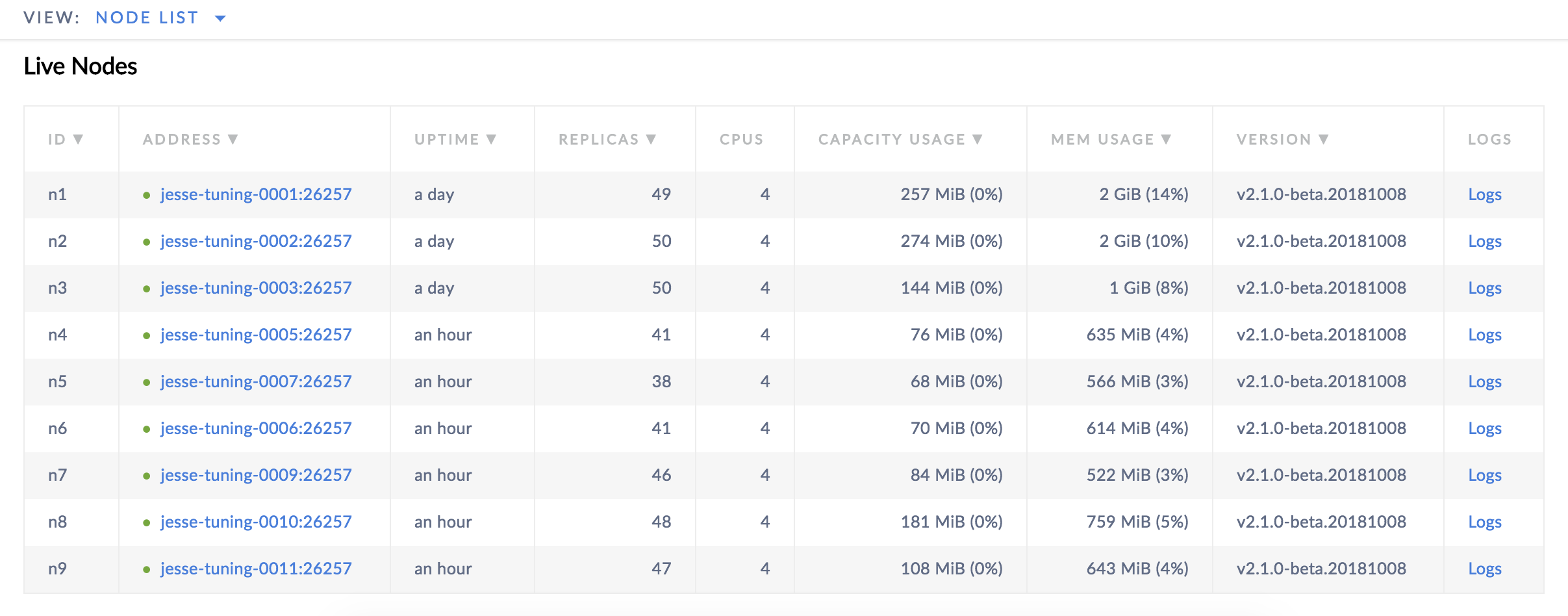
To check at a more granular level, SSH to one of the instances not running CockroachDB and run the SHOW EXPERIMENTAL_RANGES statement on the vehicles table:
$ cockroach sql \
--insecure \
--host=<address of any node> \
--database=movr \
--execute="SELECT * FROM \
[SHOW EXPERIMENTAL_RANGES FROM TABLE vehicles] \
WHERE \"start_key\" IS NOT NULL \
AND \"start_key\" NOT LIKE '%Prefix%';"
start_key | end_key | range_id | replicas | lease_holder
+------------------+----------------------------+----------+----------+--------------+
/"boston" | /"boston"/PrefixEnd | 105 | {1,2,3} | 3
/"los angeles" | /"los angeles"/PrefixEnd | 121 | {7,8,9} | 8
/"new york" | /"new york"/PrefixEnd | 101 | {1,2,3} | 3
/"san francisco" | /"san francisco"/PrefixEnd | 117 | {7,8,9} | 8
/"seattle" | /"seattle"/PrefixEnd | 113 | {4,5,6} | 5
/"washington dc" | /"washington dc"/PrefixEnd | 109 | {1,2,3} | 1
(6 rows)
For reference, here's how the nodes map to zones:
| Node IDs | Zone |
|---|---|
| 1-3 | us-east1-b (South Carolina) |
| 4-6 | us-west1-a (Oregon) |
| 7-9 | us-west2-a (Los Angeles) |
We can see that, after partitioning, the replicas for New York, Boston, and Washington DC are located on nodes 1-3 in us-east1-b, replicas for Seattle are located on nodes 4-6 in us-west1-a, and replicas for San Francisco and Los Angeles are located on nodes 7-9 in us-west2-a.
Step 15. Test performance after partitioning
After partitioning, reads and writers for a specific city will be much faster because all replicas for that city are now located on the nodes closest to the city.
To check this, let's repeat a few of the read and write queries that we executed before partitioning in step 12.
Reads
Again imagine we are a Movr administrator in New York, and we want to get the IDs and descriptions of all New York-based bikes that are currently in use:
SSH to the instance in
us-east1-bwith the Python client.Query for the data:
$ ./tuning.py \ --host=<address of a node in us-east1-b> \ --statement="SELECT id, ext FROM vehicles \ WHERE city = 'new york' \ AND type = 'bike' \ AND status = 'in_use'" \ --repeat=50 \ --timesResult: ['id', 'ext'] ['0068ee24-2dfb-437d-9a5d-22bb742d519e', "{u'color': u'green', u'brand': u'Kona'}"] ['01b80764-283b-4232-8961-a8d6a4121a08', "{u'color': u'green', u'brand': u'Pinarello'}"] ['02a39628-a911-4450-b8c0-237865546f7f', "{u'color': u'black', u'brand': u'Schwinn'}"] ['02eb2a12-f465-4575-85f8-a4b77be14c54', "{u'color': u'black', u'brand': u'Pinarello'}"] ['02f2fcc3-fea6-4849-a3a0-dc60480fa6c2', "{u'color': u'red', u'brand': u'FujiCervelo'}"] ['034d42cf-741f-428c-bbbb-e31820c68588', "{u'color': u'yellow', u'brand': u'Santa Cruz'}"] ... Times (milliseconds): [20.065784454345703, 7.866144180297852, 8.362054824829102, 9.08803939819336, 7.925987243652344, 7.543087005615234, 7.786035537719727, 8.227825164794922, 7.907867431640625, 7.654905319213867, 7.793903350830078, 7.627964019775391, 7.833957672119141, 7.858037948608398, 7.474184036254883, 9.459972381591797, 7.726192474365234, 7.194995880126953, 7.364034652709961, 7.25102424621582, 7.650852203369141, 7.663965225219727, 9.334087371826172, 7.810115814208984, 7.543087005615234, 7.134914398193359, 7.922887802124023, 7.220029830932617, 7.606029510498047, 7.208108901977539, 7.333993911743164, 7.464170455932617, 7.679939270019531, 7.436990737915039, 7.62486457824707, 7.235050201416016, 7.420063018798828, 7.795095443725586, 7.39598274230957, 7.546901702880859, 7.582187652587891, 7.9669952392578125, 7.418155670166016, 7.539033889770508, 7.805109024047852, 7.086992263793945, 7.069826126098633, 7.833957672119141, 7.43412971496582, 7.035017013549805] Median time (milliseconds): 7.62641429901
Before partitioning, this query took a median time of 72.02ms. After partitioning, the query took a median time of only 7.62ms.
Writes
Now let's again imagine 100 people in New York and 100 people in Seattle and 100 people in New York want to create new Movr accounts:
SSH to the instance in
us-west1-awith the Python client.Create 100 Seattle-based users:
./tuning.py \ --host=<address of a node in us-west1-a> \ --statement="INSERT INTO users VALUES (gen_random_uuid(), 'seattle', 'Seatller', '111 East Street', '1736352379937347')" \ --repeat=100 \ --timesTimes (milliseconds): [41.8248176574707, 9.701967239379883, 8.725166320800781, 9.058952331542969, 7.819175720214844, 6.247997283935547, 10.265827178955078, 7.627964019775391, 9.120941162109375, 7.977008819580078, 9.247064590454102, 8.929967880249023, 9.610176086425781, 14.40286636352539, 8.588075637817383, 8.67319107055664, 9.417057037353516, 7.652044296264648, 8.917093276977539, 9.135961532592773, 8.604049682617188, 9.220123291015625, 7.578134536743164, 9.096860885620117, 8.942842483520508, 8.63790512084961, 7.722139358520508, 13.59701156616211, 9.176015853881836, 11.484146118164062, 9.212017059326172, 7.563114166259766, 8.793115615844727, 8.80289077758789, 7.827043533325195, 7.6389312744140625, 17.47584342956543, 9.436845779418945, 7.63392448425293, 8.594989776611328, 9.002208709716797, 8.93402099609375, 8.71896743774414, 8.76307487487793, 8.156061172485352, 8.729934692382812, 8.738040924072266, 8.25190544128418, 8.971929550170898, 7.460832595825195, 8.889198303222656, 8.45789909362793, 8.761167526245117, 10.223865509033203, 8.892059326171875, 8.961915969848633, 8.968114852905273, 7.750988006591797, 7.761955261230469, 9.199142456054688, 9.02700424194336, 9.509086608886719, 9.428977966308594, 7.902860641479492, 8.940935134887695, 8.615970611572266, 8.75401496887207, 7.906913757324219, 8.179187774658203, 11.447906494140625, 8.71419906616211, 9.202003479003906, 9.263038635253906, 9.089946746826172, 8.92496109008789, 10.32114028930664, 7.913827896118164, 9.464025497436523, 10.612010955810547, 8.78596305847168, 8.878946304321289, 7.575035095214844, 10.657072067260742, 8.777856826782227, 8.649110794067383, 9.012937545776367, 8.931875228881836, 9.31406021118164, 9.396076202392578, 8.908987045288086, 8.002996444702148, 9.089946746826172, 7.5588226318359375, 8.918046951293945, 12.117862701416016, 7.266998291015625, 8.074045181274414, 8.955001831054688, 8.868932723999023, 8.755922317504883] Median time (milliseconds): 8.90052318573Before partitioning, this query took a median time of 48.40ms. After partitioning, the query took a median time of only 8.90ms.
SSH to the instance in
us-east1-bwith the Python client.Create 100 new NY-based users:
./tuning.py \ --host=<address of a node in us-east1-b> \ --statement="INSERT INTO users VALUES (gen_random_uuid(), 'new york', 'New Yorker', '111 West Street', '9822222379937347')" \ --repeat=100 \ --timesTimes (milliseconds): [276.3068675994873, 9.830951690673828, 8.772134780883789, 9.304046630859375, 8.24880599975586, 7.959842681884766, 7.848978042602539, 7.879018783569336, 7.754087448120117, 10.724067687988281, 13.960123062133789, 9.825944900512695, 9.60993766784668, 9.273052215576172, 9.41920280456543, 8.040904998779297, 16.484975814819336, 10.178089141845703, 8.322000503540039, 9.468793869018555, 8.002042770385742, 9.185075759887695, 9.54294204711914, 9.387016296386719, 9.676933288574219, 13.051986694335938, 9.506940841674805, 12.327909469604492, 10.377168655395508, 15.023946762084961, 9.985923767089844, 7.853031158447266, 9.43303108215332, 9.164094924926758, 10.941028594970703, 9.37199592590332, 12.359857559204102, 8.975028991699219, 7.728099822998047, 8.310079574584961, 9.792089462280273, 9.448051452636719, 8.057117462158203, 9.37795639038086, 9.753942489624023, 9.576082229614258, 8.192062377929688, 9.392023086547852, 7.97581672668457, 8.165121078491211, 9.660959243774414, 8.270978927612305, 9.901046752929688, 8.085966110229492, 10.581016540527344, 9.831905364990234, 7.883787155151367, 8.077859878540039, 8.161067962646484, 10.02812385559082, 7.9898834228515625, 9.840965270996094, 9.452104568481445, 9.747028350830078, 9.003162384033203, 9.206056594848633, 9.274005889892578, 7.8449249267578125, 8.827924728393555, 9.322881698608398, 12.08186149597168, 8.76307487487793, 8.353948593139648, 8.182048797607422, 7.736921310424805, 9.31406021118164, 9.263992309570312, 9.282112121582031, 7.823944091796875, 9.11712646484375, 8.099079132080078, 9.156942367553711, 8.363962173461914, 10.974884033203125, 8.729934692382812, 9.2620849609375, 9.27591323852539, 8.272886276245117, 8.25190544128418, 8.093118667602539, 9.259939193725586, 8.413076400756836, 8.198976516723633, 9.95182991027832, 8.024930953979492, 8.895158767700195, 8.243083953857422, 9.076833724975586, 9.994029998779297, 10.149955749511719] Median time (milliseconds): 9.26303863525Before partitioning, this query took a median time of 116.86ms. After partitioning, the query took a median time of only 9.26ms.
See also
Was this helpful?