
The EXPLAIN statement returns CockroachDB's query plan for an explainable statement. You can then use this information to optimize the query.
To actually execute a statement and return a physical query plan with execution statistics, use EXPLAIN ANALYZE.
Query optimization
Using EXPLAIN's output, you can optimize your queries by taking the following points into consideration:
Queries with fewer levels execute more quickly. Restructuring queries to require fewer levels of processing will generally improve performance.
Avoid scanning an entire table, which is the slowest way to access data. You can avoid this by creating indexes that contain at least one of the columns that the query is filtering in its
WHEREclause.
You can find out if your queries are performing entire table scans by using EXPLAIN to see which:
Indexes the query uses; shown as the Description value of rows with the Field value of
tableKey values in the index are being scanned; shown as the Description value of rows with the Field value of
spans
For more information, see Find the Indexes and Key Ranges a Query Uses.
Synopsis
Required privileges
The user requires the appropriate privileges for the statement being explained.
Parameters
| Parameter | Description |
|---|---|
VERBOSE |
Show as much information as possible about the query plan. |
TYPES |
Include the intermediate data types CockroachDB chooses to evaluate intermediate SQL expressions. |
OPT |
New in v2.1: Display a query plan tree if the query will be run with the cost-based optimizer. If it returns an "unsupported statement" error, the query will not be run with the cost-based optimizer and will be run with the heuristic planner. |
DISTSQL |
New in v2.1: Generate a link to a distributed SQL physical query plan tree. |
preparable_stmt |
The statement you want details about. All preparable statements are explainable. |
EXPLAIN also includes other modes besides query plans that are useful only to CockroachDB developers, which are not documented here.
Success responses
Successful EXPLAIN statements return tables with the following columns:
| Column | Description |
|---|---|
| Tree | A tree representation showing the hierarchy of the query plan. |
| Field | The name of a parameter relevant to the query plan node immediately above. |
| Description | Additional information for the parameter in Field. |
| Columns | The columns provided to the processes at lower levels of the hierarchy. Included in TYPES and VERBOSE output. |
| Ordering | The order in which results are presented to the processes at each level of the hierarchy, as well as other properties of the result set at each level. Included in TYPES and VERBOSE output. |
Examples
Default query plans
By default, EXPLAIN includes the least detail about the query plan but can be useful to find out which indexes and index key ranges are used by a query:
EXPLAIN SELECT * FROM kv WHERE v > 3 ORDER BY v;
tree | field | description
+-----------+--------+-------------+
sort | |
│ | order | +v
└── scan | |
| table | kv@primary
| spans | ALL
| filter | v > 3
(6 rows)
The first column shows the tree structure of the query plan; a set of properties is displayed for each node in the tree. Most importantly, for scans, you can see the index that is scanned (primary in this case) and what key ranges of the index you are scanning (in this case, a full table scan). For more information on indexes and key ranges, see the example below.
VERBOSE option
The VERBOSE option:
- Includes SQL expressions that are involved in each processing stage, providing more granular detail about which portion of your query is represented at each level.
- Includes detail about which columns are being used by each level, as well as properties of the result set on that level.
EXPLAIN (VERBOSE) SELECT * FROM kv AS a JOIN kv USING (k) WHERE a.v > 3 ORDER BY a.v DESC;
tree | field | description | columns | ordering
+---------------------+----------------+-------------+--------------+----------+
sort | | | (k, v, v) | -v
│ | order | -v | |
└── render | | | (k, v, v) |
│ | render 0 | k | |
│ | render 1 | v | |
│ | render 2 | v | |
└── join | | | (k, v, k, v) |
│ | type | inner | |
│ | equality | (k) = (k) | |
│ | mergeJoinOrder | +"(k=k)" | |
├── scan | | | (k, v) | +k
│ | table | kv@primary | |
│ | spans | ALL | |
│ | filter | v > 3 | |
└── scan | | | (k, v) | +k
| table | kv@primary | |
| spans | ALL | |
(17 rows)
TYPES option
The TYPES mode includes the types of the values used in the query plan. It also includes the SQL expressions that were involved in each processing stage, and includes the columns used by each level.
EXPLAIN (TYPES) SELECT * FROM kv WHERE v > 3 ORDER BY v;
tree | field | description | columns | ordering
+-----------+--------+-----------------------------+----------------+----------+
sort | | | (k int, v int) | +v
│ | order | +v | |
└── scan | | | (k int, v int) |
| table | kv@primary | |
| spans | ALL | |
| filter | ((v)[int] > (3)[int])[bool] | |
(6 rows)
OPT option
New in v2.1: The OPT option displays a query plan tree, along with some information that was used to plan the query, if the query will be run with the cost-based optimizer. If it returns an "unsupported statement" error, the query will not be run with the cost-based optimizer and will be run with the legacy heuristic planner.
For example, the following query returns the query plan tree, which means that it will be run with the cost-based optimizer:
EXPLAIN(OPT) SELECT l_shipmode, avg(l_extendedprice) from lineitem GROUP BY l_shipmode;
text
+-----------------------------------------------------------------------------+
group-by
├── columns: l_shipmode:15(string!null) avg:17(float)
├── grouping columns: l_shipmode:15(string!null)
├── stats: [rows=700, distinct(15)=700]
├── cost: 1207
├── key: (15)
├── fd: (15)-->(17)
├── prune: (17)
├── scan lineitem
│ ├── columns: l_extendedprice:6(float!null) l_shipmode:15(string!null)
│ ├── stats: [rows=1000, distinct(15)=700]
│ ├── cost: 1180
│ └── prune: (6,15)
└── aggregations [outer=(6)]
└── avg [type=float, outer=(6)]
└── variable: l_extendedprice [type=float, outer=(6)]
(16 rows)
In contrast, this query returns pq: unsupported statement: *tree.Insert, which means that it will use the heuristic planner instead of the cost-based optimizer:
EXPLAIN (OPT) INSERT INTO l_shipmode VALUES ("truck");
pq: unsupported statement: *tree.Insert
DISTSQL option
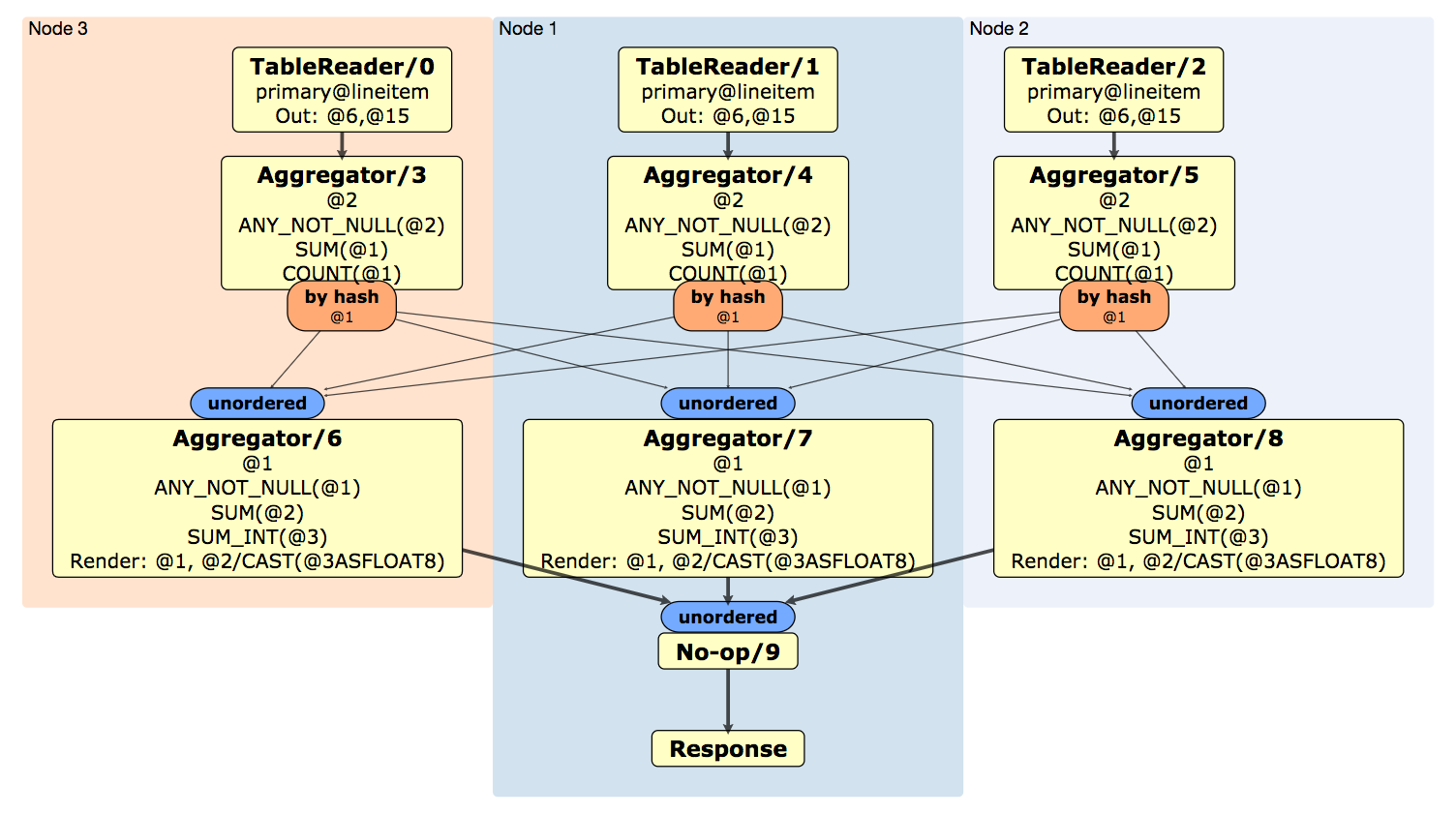
New in v2.1: The DISTSQL option generates a physical query plan for a query. Query plans provide information around SQL execution, which can be used to troubleshoot slow queries. For more information about distributed SQL queries, see the DistSQL section of our SQL Layer Architecture docs.
EXPLAIN (DISTSQL) generates a physical query plan that provides high level information about how a query will be executed:
EXPLAIN (DISTSQL) SELECT l_shipmode, AVG(l_extendedprice) FROM lineitem GROUP BY l_shipmode;
automatic | url
-----------+----------------------------------------------
true | https://cockroachdb.github.io/distsqlplan...
To view the DistSQL Plan Viewer, point your browser to the URL provided:
Find the indexes and key ranges a query uses
You can use EXPLAIN to understand which indexes and key ranges queries use, which can help you ensure a query isn't performing a full table scan.
CREATE TABLE kv (k INT PRIMARY KEY, v INT);
Because column v is not indexed, queries filtering on it alone scan the entire table:
EXPLAIN SELECT * FROM kv WHERE v BETWEEN 4 AND 5;
tree | field | description
+------+--------+-----------------------+
scan | |
| table | kv@primary
| spans | ALL
| filter | (v >= 4) AND (v <= 5)
(4 rows)
If there were an index on v, CockroachDB would be able to avoid scanning the entire table:
CREATE INDEX v ON kv (v);
EXPLAIN SELECT * FROM kv WHERE v BETWEEN 4 AND 5;
tree | field | description
------+-------+-------------
scan | |
| table | kv@v
| spans | /4-/6
(3 rows)
Now, only part of the index v is getting scanned, specifically the key range starting at (and including) 4 and stopping before 6.
See also
ALTER TABLEALTER SEQUENCEBACKUPCANCEL JOBCREATE DATABASEDROP DATABASEEXECUTEEXPLAIN ANALYZEIMPORT- Indexes
INSERTPAUSE JOBRESETRESTORERESUME JOBSELECT- Selection Queries
SETSET CLUSTER SETTINGSHOW COLUMNSUPDATEUPSERT
Was this helpful?