
Once you've installed CockroachDB, it's simple to run an insecure multi-node cluster locally.
To deploy a free CockroachDB Cloud cluster instead of running CockroachDB yourself, see the Quickstart.
Before you begin
- Make sure you have already installed CockroachDB.
- For quick SQL testing or app development, consider running a single-node cluster instead.
- Running multiple nodes on a single host is useful for testing CockroachDB, but it's not suitable for production. To run a physically distributed cluster, refer to Manual Deployment or Orchestrated Deployment, and review the Production Checklist.
Reusing a previously initialized store when starting a new cluster is not recommended. If the store is incompatible with either the new CockroachDB binary or the new cluster configuration, this can lead to panics or other problems when starting a cluster. Instead, either move or delete the previous store directory before starting the cockroach process. An example of an incompatible configuration is if the new cluster is started with the --start-single-node flag, which disables replication, when the cluster configuration in the store has replication enabled.
The store directory is cockroach-data/ in the same directory as the cockroach command by default, or the location passed to the --store flag otherwise. For details about configuring the store location, refer to cockroach start.
Step 1. Start the cluster
This section shows how to start a cluster interactively. In production, operators usually use a process manager like systemd to start and manage the cockroach process on each node. Refer to Deploy CockroachDB On-Premises.
Use the
cockroach startcommand to start thenode1in the foreground:cockroach start \ --insecure \ --store=node1 \ --listen-addr=localhost:26257 \ --http-addr=localhost:8080 \ --join=localhost:26257,localhost:26258,localhost:26259Note:The
--backgroundflag is not recommended. If you decide to start nodes in the background, you must also pass the--pid-fileargument. To stop acockroachprocess running in the background, extract the process ID from the PID file and pass it to the command to stop the node.In production, operators usually use a process manager like
systemdto start and manage thecockroachprocess on each node. Refer to Deploy CockroachDB On-Premises.You'll see a message like the following:
* * WARNING: RUNNING IN INSECURE MODE! * * - Your cluster is open for any client that can access localhost. * - Any user, even root, can log in without providing a password. * - Any user, connecting as root, can read or write any data in your cluster. * - There is no network encryption nor authentication, and thus no confidentiality. * * Check out how to secure your cluster: https://www.cockroachlabs.com/docs/v24.1/secure-a-cluster.html * * * INFO: initial startup completed. * Node will now attempt to join a running cluster, or wait for `cockroach init`. * Client connections will be accepted after this completes successfully. * Check the log file(s) for progress. *Take a moment to understand the flags you used:
- The
--insecureflag makes communication unencrypted. - Since this is a purely local cluster,
--listen-addr=localhost:26257and--http-addr=localhost:8080tell the node to listen only onlocalhost, with port26257used for internal and client traffic and port8080used for HTTP requests from the DB Console. - The
--storeflag indicates the location where the node's data and logs are stored. The
--joinflag specifies the addresses and ports of the nodes that will initially comprise your cluster. You'll use this exact--joinflag when starting other nodes as well.For a cluster in a single region, set 3-5
--joinaddresses. Each starting node will attempt to contact one of the join hosts. In case a join host cannot be reached, the node will try another address on the list until it can join the gossip network.
- The
In new terminal windows, start
node2andnode3:cockroach start \ --insecure \ --store=node2 \ --listen-addr=localhost:26258 \ --http-addr=localhost:8081 \ --join=localhost:26257,localhost:26258,localhost:26259cockroach start \ --insecure \ --store=node3 \ --listen-addr=localhost:26259 \ --http-addr=localhost:8082 \ --join=localhost:26257,localhost:26258,localhost:26259These commands are the same as before but with unique
--store,--listen-addr, and--http-addrflags.Use the
cockroach initcommand to perform a one-time initialization of the cluster, sending the request to any node on the--joinlist:cockroach init --insecure --host=localhost:26257You'll see the following message:
Cluster successfully initializedAt this point, each node also prints helpful startup details to its log, and to
STDOUTin the terminal window where the node was started. For example, the following command retrievesnode1's startup details:grep 'node starting' node1/logs/cockroach.log -A 11The output will look something like this:
CockroachDB node starting at build: CCL v24.1.3 @ 2024-08-01 00:00:00 (go1.12.6) webui: http://localhost:8080 sql: postgresql://root@localhost:26257?sslmode=disable RPC client flags: cockroach <client cmd> --host=localhost:26257 --insecure logs: /Users/<username>/node1/logs temp dir: /Users/<username>/node1/cockroach-temp242232154 external I/O path: /Users/<username>/node1/extern store[0]: path=/Users/<username>/node1 status: initialized new cluster clusterID: 8a681a16-9623-4fc1-a537-77e9255daafd nodeID: 1
Step 2. Use the built-in SQL client
Now that your cluster is live, you can use any node as a SQL gateway. To test this out, let's use CockroachDB's built-in SQL client.
In a new terminal, run the cockroach sql command and connect to
node1:cockroach sql --insecure --host=localhost:26257To exit the SQL shell at any time, you can use the
\qcommand:\qRun some basic CockroachDB SQL statements:
CREATE DATABASE bank;CREATE TABLE bank.accounts (id INT PRIMARY KEY, balance DECIMAL);INSERT INTO bank.accounts VALUES (1, 1000.50);SELECT * FROM bank.accounts;id | balance +----+---------+ 1 | 1000.50 (1 row)In a new terminal window, open a new SQL shell and connect to
node2:cockroach sql --insecure --host=localhost:26258Note:In a real deployment, all nodes would likely use the default port
26257, and so you wouldn't need to set the port portion of--host.Run the same
SELECTquery as before:SELECT * FROM bank.accounts;id | balance +----+---------+ 1 | 1000.50 (1 row)As you can see, node 1 and node 2 behaved identically as SQL gateways.
Exit all SQL shell sessions by issuing the
\qcommand in the terminals where they are running:\q
Step 3. Run a sample workload
CockroachDB also comes with a number of built-in workloads for simulating client traffic. Let's run the workload based on CockroachDB's sample vehicle-sharing application, MovR.
Load the initial dataset:
cockroach workload init movr \ 'postgresql://root@localhost:26257?sslmode=disable'I190926 16:50:35.663708 1 workload/workloadsql/dataload.go:135 imported users (0s, 50 rows) I190926 16:50:35.682583 1 workload/workloadsql/dataload.go:135 imported vehicles (0s, 15 rows) I190926 16:50:35.769572 1 workload/workloadsql/dataload.go:135 imported rides (0s, 500 rows) I190926 16:50:35.836619 1 workload/workloadsql/dataload.go:135 imported vehicle_location_histories (0s, 1000 rows) I190926 16:50:35.915498 1 workload/workloadsql/dataload.go:135 imported promo_codes (0s, 1000 rows)Run the workload for 5 minutes:
cockroach workload run movr \ --duration=5m \ 'postgresql://root@localhost:26257?sslmode=disable'
Step 4. Access the DB Console
The CockroachDB DB Console gives you insight into the overall health of your cluster as well as the performance of the client workload.
Go to http://localhost:8080.
On the Cluster Overview, notice that three nodes are live, with an identical replica count on each node:
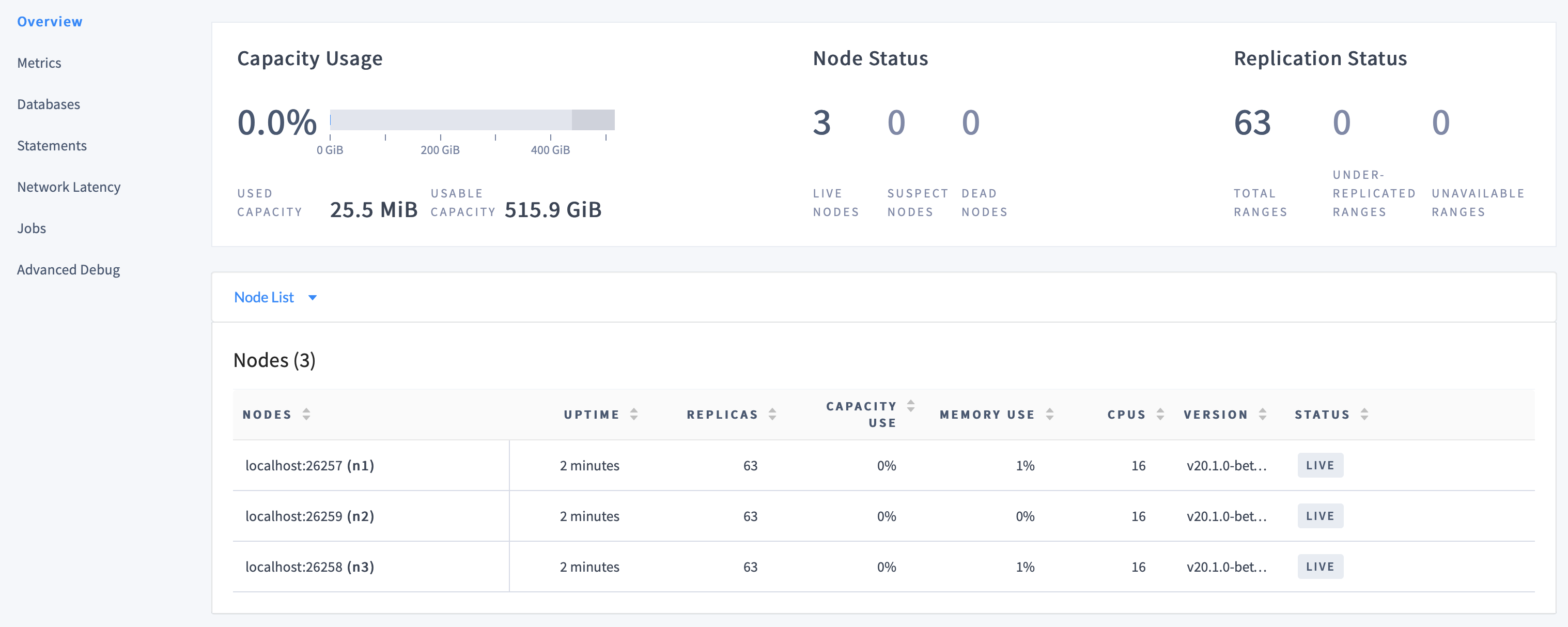
This demonstrates CockroachDB's automated replication of data via the Raft consensus protocol.
Note:Capacity metrics can be incorrect when running multiple nodes on a single machine. For more details, see this limitation.
Click Metrics to access a variety of time series dashboards, including graphs of SQL queries and service latency over time:
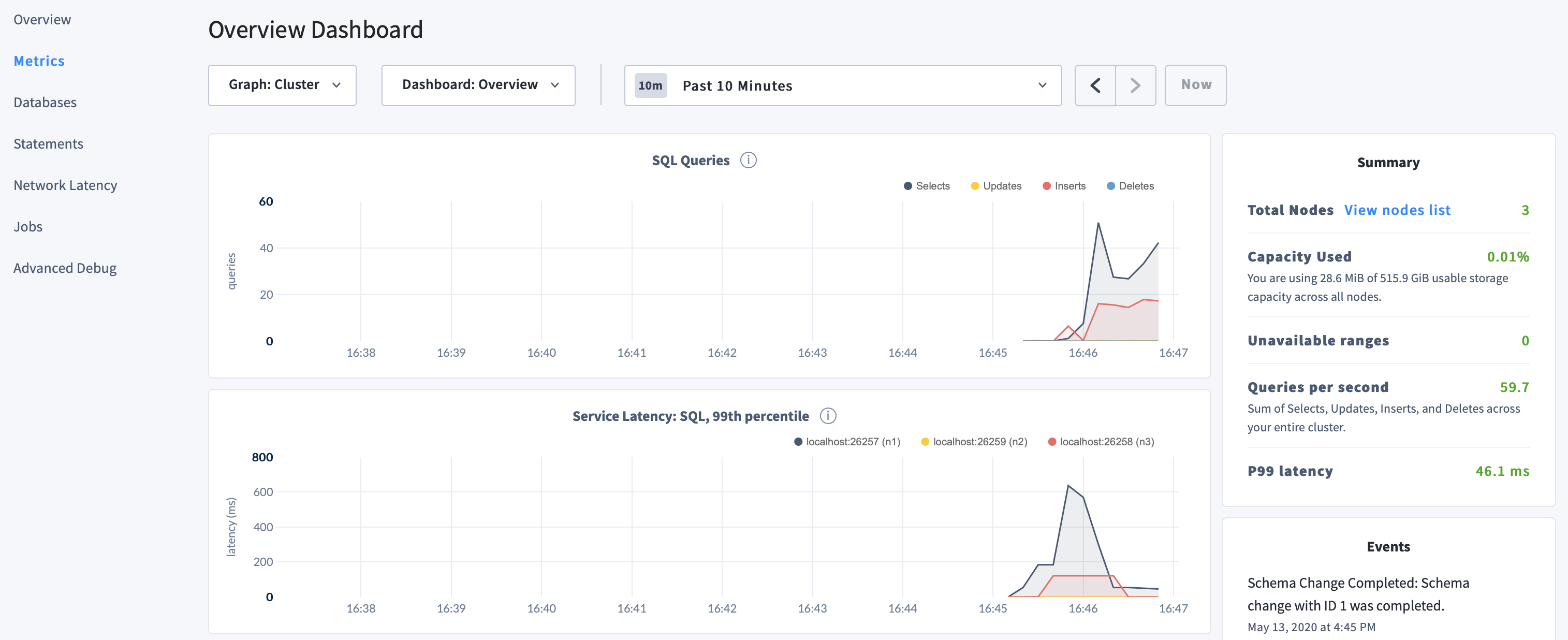
Use the Databases, Statements, and Jobs pages to view details about your databases and tables, to assess the performance of specific queries, and to monitor the status of long-running operations like schema changes, respectively.
Step 5. Simulate node maintenance
In a new terminal, gracefully shut down a node. This is normally done prior to node maintenance:
Get the process IDs of the nodes:
ps -ef | grep cockroach | grep -v grep501 4482 1 0 2:41PM ttys000 0:09.78 cockroach start --insecure --store=node1 --listen-addr=localhost:26257 --http-addr=localhost:8080 --join=localhost:26257,localhost:26258,localhost:26259 501 4497 1 0 2:41PM ttys000 0:08.54 cockroach start --insecure --store=node2 --listen-addr=localhost:26258 --http-addr=localhost:8081 --join=localhost:26257,localhost:26258,localhost:26259 501 4503 1 0 2:41PM ttys000 0:08.54 cockroach start --insecure --store=node3 --listen-addr=localhost:26259 --http-addr=localhost:8082 --join=localhost:26257,localhost:26258,localhost:26259Gracefully shut down
node3, specifying its process ID:kill -TERM 4503In the DB Console, despite one node being "suspect", notice the continued SQL traffic:
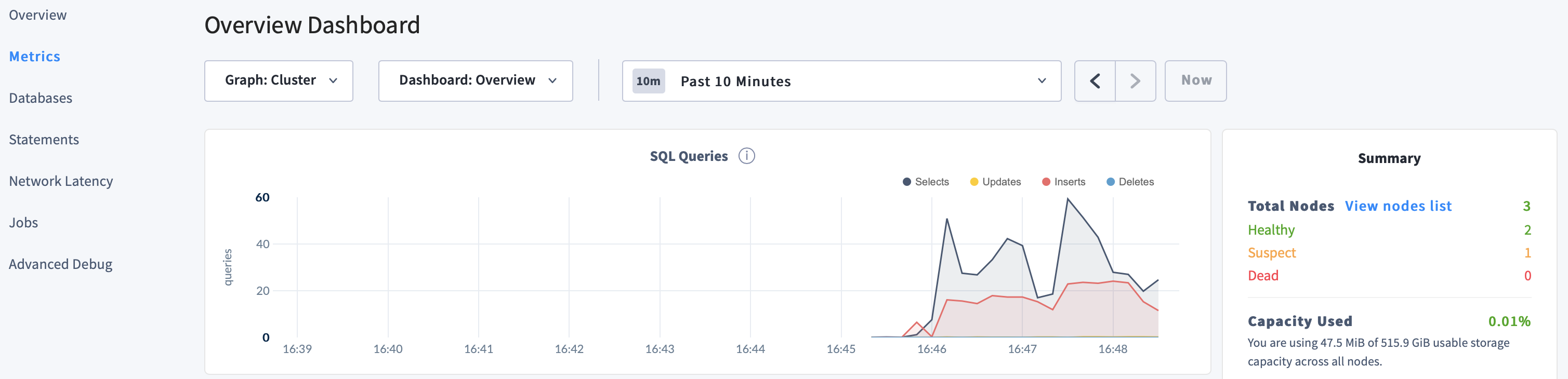
Go to the terminal window for
node3and restart it:cockroach start \ --insecure \ --store=node3 \ --listen-addr=localhost:26259 \ --http-addr=localhost:8082 \ --join=localhost:26257,localhost:26258,localhost:26259
Step 6. Scale the cluster
Adding capacity is as simple as starting more nodes with cockroach start.
In new terminal windows, start two more nodes:
cockroach start \ --insecure \ --store=node4 \ --listen-addr=localhost:26260 \ --http-addr=localhost:8083 \ --join=localhost:26257,localhost:26258,localhost:26259cockroach start \ --insecure \ --store=node5 \ --listen-addr=localhost:26261 \ --http-addr=localhost:8084 \ --join=localhost:26257,localhost:26258,localhost:26259Again, these commands are the same as before but with unique
--store,--listen-addr, and--http-addrflags.In the DB Console Cluster Overview page, confirm that the cluster now has five nodes.
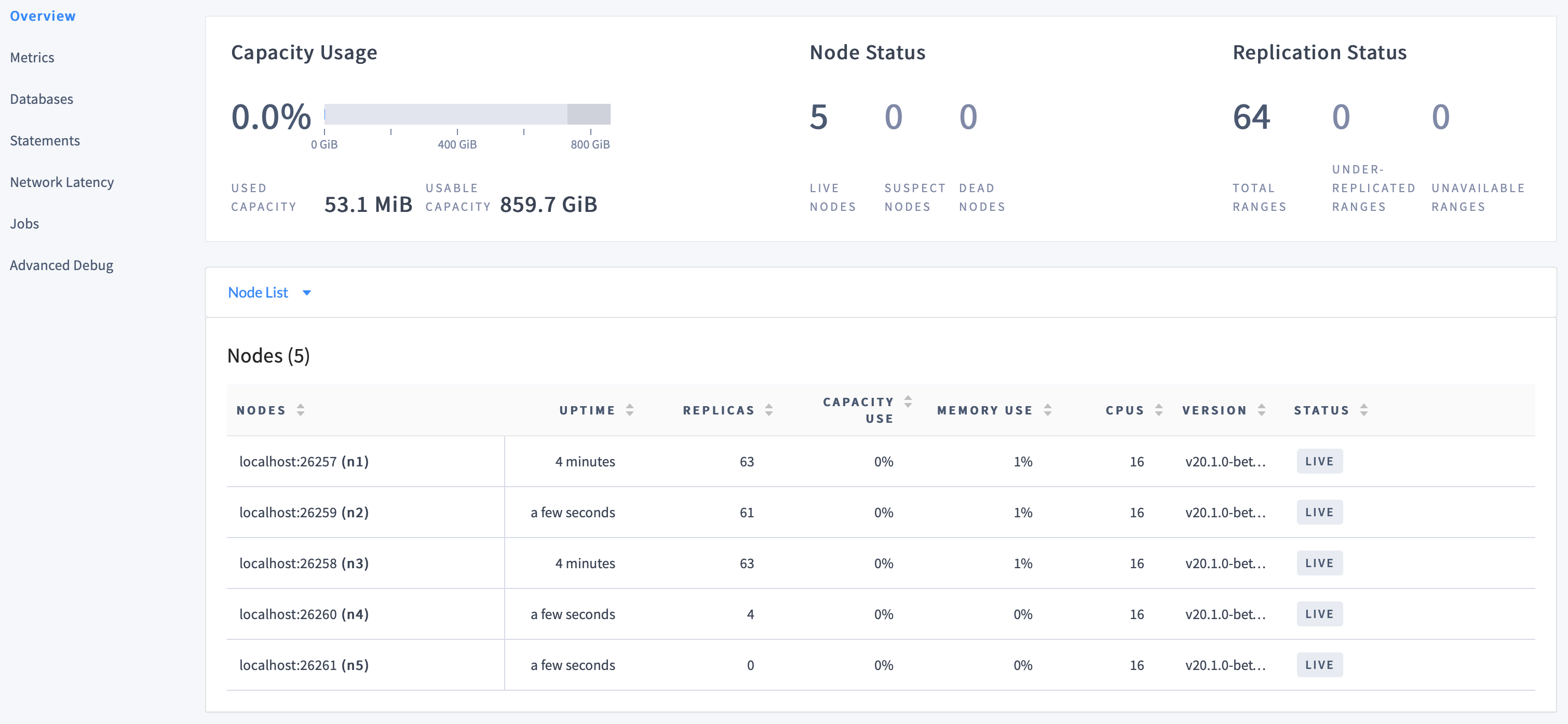
At first, the replica count will be lower for
node4andnode5. Very soon, however, you'll see those numbers even out across all nodes, indicating that data is being automatically rebalanced to utilize the additional capacity of the new nodes.
Step 7. Stop the cluster
When you're done with your test cluster, stop the nodes.
Get the process IDs of the nodes:
ps -ef | grep cockroach | grep -v grep501 4482 1 0 2:41PM ttys000 0:09.78 cockroach start --insecure --store=node1 --listen-addr=localhost:26257 --http-addr=localhost:8080 --join=localhost:26257,localhost:26258,localhost:26259 501 4497 1 0 2:41PM ttys000 0:08.54 cockroach start --insecure --store=node2 --listen-addr=localhost:26258 --http-addr=localhost:8081 --join=localhost:26257,localhost:26258,localhost:26259 501 4503 1 0 2:41PM ttys000 0:08.54 cockroach start --insecure --store=node3 --listen-addr=localhost:26259 --http-addr=localhost:8082 --join=localhost:26257,localhost:26258,localhost:26259 501 4510 1 0 2:42PM ttys000 0:08.46 cockroach start --insecure --store=node4 --listen-addr=localhost:26260 --http-addr=localhost:8083 --join=localhost:26257,localhost:26258,localhost:26259 501 4622 1 0 2:43PM ttys000 0:02.51 cockroach start --insecure --store=node5 --listen-addr=localhost:26261 --http-addr=localhost:8084 --join=localhost:26257,localhost:26258,localhost:26259Gracefully shut down each node by sending the
SIGTERMsignal to thecockroachprocess:kill -TERM 4482Repeat this command for each node.
Note:For
node4andnode5, the shutdown process will take longer (about a minute each) and will eventually force the nodes to stop. Because only two of the five nodes are now running, the cluster has lost quorum and is no longer operational.To restart the cluster at a later time, run the same
cockroach startcommands as earlier from the directory containing the nodes' data stores.If you do not plan to restart the cluster, you may want to remove the nodes' data stores:
rm -rf node1 node2 node3 node4 node5
What's next?
- Install the client driver for your preferred language
- Learn more about CockroachDB SQL and the built-in SQL client
- Build an app with CockroachDB
- Further explore CockroachDB capabilities like fault tolerance and automated repair, multi-region performance, serializable transactions, and JSON support
Was this helpful?